String
Table of contents
- Reverse String
- Longest Common Prefix
- Reverse Words in a String
- First Unique or Non Repeated Character in a String
- String indexOf() custom method
- Test
- Longest Substring Without Repeating Characters
- Valid Parentheses
- Add Strings
- Valid Anagram
- Group Anagrams
- Find the Difference
- Valid Parenthesis String
- Remove Invalid Parentheses
- Valid Palindrome
- First Unique Character in a String
- Maximum Number of Occurrences of a Substring
- Longest Palindromic Substring
- Determine if Two Events Have Conflict
- Word Search
- Permutation in String
- Balanced Binary Tree
- Zigzag Conversion
- Validate Binary Search Tree
- Remove Duplicates from Sorted Array II
- Backspace String Compare
- Palindromic Substrings
- Valid Palindrome II
- Reverse String
- String To Integer
- Remove Duplicate Letters
- Search Suggestions System
- Decode Ways
- More Details:
Reverse String
Write a function that reverses a string. The input string is given as an array of characters s.
You must do this by modifying the input array in-place with O(1) extra memory.
Example:
Input: s = [“h”,”e”,”l”,”l”,”o”]
Output: [“o”,”l”,”l”,”e”,”h”]
Solution1
Two pointers i and j, pointing to the beginning and end, respectively. While i < j, swap. Using a helper swap function severely impacts runtime and memory, so we swap in the loop.
Implementation
class Solution {
public void reverseString(char[] s) {
int len = s.length;
int left = 0;
int right = s.length - 1;
while(left < right) {
char tmp = s[left];
s[left] = s[right];
s[right] = tmp;
left++;
right--;
}
}
}
Runtime
3 ms
Memory
52.6 MB
Complexity Analysis
Time Complexity:
We are iterating half array hence it will take O(n/2) which will become O(n).
Space Complexity:
O(1)
Solution2
Using for loop swap.
Implementation
class Solution {
public void reverseString(char[] s) {
for (int i = 0; i < s.length / 2; i++) { //Do it half the number of String length
char tmp = s[i];
s[i] = s[s.length - 1 - i]; //Front swap with other End side
s[s.length - 1 - i] = tmp; //End swap with other Front side
}
}
}
Runtime
1 ms
Memory
52.7 MB
Complexity Analysis
Time Complexity:
We are iterating half array hence it will take O(n/2) which will become O(n).
Space Complexity:
O(1)
Solution3
Add to extra space from rear to front then Set reversed ‘str’ into char array ‘s’
Implementation
class Solution {
public void reverseString(char[] s) {
String str = ""; //Allocate extra space
for (int i = s.length - 1; i >= 0; i--) /*Add to extra space from rear to front */
str += s[i];
for (int i = 0; i < s.length; i++) /*Set reversed 'str' into char array 's' */
s[i] = str.charAt(i);
}
}
Solution4
Using StringBuilder reverse method.
Implementation
return new StringBuilder(s).reverse().toString();
Longest Common Prefix
Write a function to find the longest common prefix string amongst an array of strings.
Iif there is no common prefix, return an empty string “”.
Example 1:
- Input: strs = [“flower”,”flow”,”flight”]
- Output: “fl”
Example 2:
- Input: strs = [“dog”,”racecar”,”car”]
- Output: “”
- Explanation: There is no common prefix among the input strings.
Solution1
- Take the first(index=0) string in the array as prefix.
- Iterate from second(index=1) string till the end.
- Use the indexOf() function to check if the prefix is there in the strs[i] or not. If the prefix is there the function returns 0 else -1.
- Use the substring function to chop the last letter from prefix each time the function return -1.
**Example :**
strs=["flower", "flow", "flight"]
prefix=flower
**index=1**
while(strs[index].indexOf(prefix) != 0) means while("flow".indexOf("flower")!=0)
Since flower as a whole is not in flow, it return -1 and prefix=prefix.substring(0,prefix.length()-1) reduces prefix to "flowe"
Again while(strs[index].indexOf(prefix) != 0) means while("flow".indexOf("flowe")!=0)
Since flowe as a whole is not in flow, it return -1 and prefix=prefix.substring(0,prefix.length()-1) reduces prefix to "flow"
Again while(strs[index].indexOf(prefix) != 0) means while("flow".indexOf("flow")!=0)
Since flow as a whole is in flow, it returns 0 so now prefix=flow
**index=2**
while(strs[index].indexOf(prefix) != 0) means while("flight".indexOf("flow")!=0)
Since flow as a whole is not in flight, it return -1 and prefix=prefix.substring(0,prefix.length()-1) reduces prefix to "flo"
Again while(strs[index].indexOf(prefix) != 0) means while("flight".indexOf("flo")!=0)
Since flo as a whole is not in flight, it return -1 and prefix=prefix.substring(0,prefix.length()-1) reduces prefix to "fl"
Again while(strs[index].indexOf(prefix) != 0) means while("flight".indexOf("fl")!=0)
Since fl as a whole is in flight, it returns 0 so now prefix=fl
**index=3**
for loop terminates and we return prefix which is equal to fl
Implementation
class Solution {
public String longestCommonPrefix(String[] strs) {
if(strs.length == 0) return "";
String prefix = strs[0];
for(int i=1; i< strs.length; i++ ) {
while(strs[i].indexOf(prefix) != 0) {
prefix = prefix.substring(0, prefix.length()-1);
}
}
return prefix;
}
}
Runtime
1 ms
Memory
39.2 MB
Complexity Analysis
Time Complexity: O(n)
Space Complexity: O(1)
Solution2
Implementation
class Solution {
public String longestCommonPrefix(String[] strs) {
if (strs == null || strs.length == 0)
return "";
Arrays.sort(strs);
String first = strs[0];
String last = strs[strs.length - 1];
int c = 0;
while(c < first.length())
{
if (first.charAt(c) == last.charAt(c))
c++;
else
break;
}
return c == 0 ? "" : first.substring(0, c);
}
}
Solution 3 :
class Solution {
public String longestCommonPrefix(String[] strs) {
String prefix = strs[0];
for(int index=1;index<strs.length;index++){
while(strs[index].indexOf(prefix) != 0){
prefix=prefix.substring(0,prefix.length()-1);
}
}
return prefix;
}
}
Working:
1)Take the first(index=0) string in the array as prefix.
2)Iterate from second(index=1) string till the end.
3)Use the indexOf() function to check if the prefix is there in the strs[i] or not. If the prefix is there the function returns 0 else -1.
4)Use the substring function to chop the last letter from prefix each time the function return -1.
eg:
-
strs=[“flower”, “flow”, “flight”]
-
prefix=flower
index=1
-
while(strs[index].indexOf(prefix) != 0) means while(“flow”.indexOf(“flower”)!=0)
-
Since flower as a whole is not in flow, it return -1 and prefix=prefix.substring(0,prefix.length()-1) reduces prefix to “flowe”
-
Again while(strs[index].indexOf(prefix) != 0) means while(“flow”.indexOf(“flowe”)!=0)
-
Since flowe as a whole is not in flow, it return -1 and prefix=prefix.substring(0,prefix.length()-1) reduces prefix to “flow”
-
Again while(strs[index].indexOf(prefix) != 0) means while(“flow”.indexOf(“flow”)!=0)
-
Since flow as a whole is in flow, it returns 0 so now prefix=flow
index=2
-
while(strs[index].indexOf(prefix) != 0) means while(“flight”.indexOf(“flow”)!=0)
-
Since flow as a whole is not in flight, it return -1 and prefix=prefix.substring(0,prefix.length()-1) reduces prefix to “flo”
-
Again while(strs[index].indexOf(prefix) != 0) means while(“flight”.indexOf(“flo”)!=0)
-
Since flo as a whole is not in flight, it return -1 and prefix=prefix.substring(0,prefix.length()-1) reduces prefix to “fl”
-
Again while(strs[index].indexOf(prefix) != 0) means while(“flight”.indexOf(“fl”)!=0)
-
Since fl as a whole is in flight, it returns 0 so now prefix=fl
index=3
for loop terminates and we return prefix which is equal to fl
Reverse Words in a String
Given an input string s, reverse the order of the words.
A word is defined as a sequence of non-space characters. The words in s will be separated by at least one space.
Return a string of the words in reverse order concatenated by a single space.
Note that s may contain leading or trailing spaces or multiple spaces between two words. The returned string should only have a single space separating the words. Do not include any extra spaces.
Example 1:
Input: s = "the sky is blue"
Output: "blue is sky the"
Example 2:
Input: s = " hello world "
Output: "world hello"
Explanation: Your reversed string should not contain leading or trailing spaces.
Example 3:
Input: s = "a good example"
Output: "example good a"
Explanation: You need to reduce multiple spaces between two words to a single space in the reversed string.
Constraints:
-
1 <= s.length <= 104 -
scontains English letters (upper-case and lower-case), digits, and spaces ` `. -
There is at least one word in
s.
Solution 1
Two-pointers solution no trim( ), no split( ), no StringBuilder
Implementation
public class Solution {
public String reverseWords(String s) {
if (s == null) return null;
char[] a = s.toCharArray();
int n = a.length;
// step 1. reverse the whole string
reverse(a, 0, n - 1);
// step 2. reverse each word
reverseWords(a, n);
// step 3. clean up spaces
return cleanSpaces(a, n);
}
void reverseWords(char[] a, int n) {
int i = 0, j = 0;
while (i < n) {
while (i < j || i < n && a[i] == ' ') i++; // skip spaces
while (j < i || j < n && a[j] != ' ') j++; // skip non spaces
reverse(a, i, j - 1); // reverse the word
}
}
// trim leading, trailing and multiple spaces
String cleanSpaces(char[] a, int n) {
int i = 0, j = 0;
while (j < n) {
while (j < n && a[j] == ' ') j++; // skip spaces
while (j < n && a[j] != ' ') a[i++] = a[j++]; // keep non spaces
while (j < n && a[j] == ' ') j++; // skip spaces
if (j < n) a[i++] = ' '; // keep only one space
}
return new String(a).substring(0, i);
}
// reverse a[] from a[i] to a[j]
private void reverse(char[] a, int i, int j) {
while (i < j) {
char t = a[i];
a[i++] = a[j];
a[j--] = t;
}
}
}
Solution 2 : Built-in Split + Reverse
Implementation
class Solution {
public String reverseWords(String s) {
// remove leading spaces
s = s.trim();
// split by multiple spaces
List<String> wordList = Arrays.asList(s.split("\\s+"));
Collections.reverse(wordList);
return String.join(" ", wordList);
}
}
Complexity Analysis
Time Complexity: O(N), where N is a number of characters in the input string.
Space Complexity: O(N), to store the result of split by spaces.
Solution 3 : Reverse the Whole String and Then Reverse Each Word
Implementation
class Solution {
public StringBuilder trimSpaces(String s) {
int left = 0, right = s.length() - 1;
// remove leading spaces
while (left <= right && s.charAt(left) == ' ') ++left;
// remove trailing spaces
while (left <= right && s.charAt(right) == ' ') --right;
// reduce multiple spaces to single one
StringBuilder sb = new StringBuilder();
while (left <= right) {
char c = s.charAt(left);
if (c != ' ') sb.append(c);
else if (sb.charAt(sb.length() - 1) != ' ') sb.append(c);
++left;
}
return sb;
}
public void reverse(StringBuilder sb, int left, int right) {
while (left < right) {
char tmp = sb.charAt(left);
sb.setCharAt(left++, sb.charAt(right));
sb.setCharAt(right--, tmp);
}
}
public void reverseEachWord(StringBuilder sb) {
int n = sb.length();
int start = 0, end = 0;
while (start < n) {
// go to the end of the word
while (end < n && sb.charAt(end) != ' ') ++end;
// reverse the word
reverse(sb, start, end - 1);
// move to the next word
start = end + 1;
++end;
}
}
public String reverseWords(String s) {
// converst string to string builder
// and trim spaces at the same time
StringBuilder sb = trimSpaces(s);
// reverse the whole string
reverse(sb, 0, sb.length() - 1);
// reverse each word
reverseEachWord(sb);
return sb.toString();
}
}
Complexity Analysis
Time complexity: O(N).
Space complexity: O(N).
Solution 4 : Deque of Words
Implementation
class Solution {
public String reverseWords(String s) {
int left = 0, right = s.length() - 1;
// remove leading spaces
while (left <= right && s.charAt(left) == ' ') ++left;
// remove trailing spaces
while (left <= right && s.charAt(right) == ' ') --right;
Deque<String> d = new ArrayDeque();
StringBuilder word = new StringBuilder();
// push word by word in front of deque
while (left <= right) {
char c = s.charAt(left);
if ((word.length() != 0) && (c == ' ')) {
d.offerFirst(word.toString());
word.setLength(0);
} else if (c != ' ') {
word.append(c);
}
++left;
}
d.offerFirst(word.toString());
return String.join(" ", d);
}
}
Complexity Analysis
Time complexity: O(N).
Space complexity: O(N).
First Unique or Non Repeated Character in a String
Find First Non Repeated Character in a String
Given a string s, find the first non-repeating character in it and return its index. If it does not exist, return -1.
Example 1:
Input: s = “leetcode” Output: 0
Example 2:
Input: s = “loveleetcode” Output: 2
Example 3:
Input: s = “aabb” Output: -1
Solution 1
Implementation
class Solution{
public int firstUniqChar(String s) {
for(char c : s.toCharArray()){
int index = s.indexOf(c);
int lastIndex = s.lastIndexOf(c);
if(index == lastIndex)
return index;
}
return -1;
}
}
Runtime
20 ms
Memory
39.5 MB
Complexity Analysis
Time Complexity: O(n^2)
Space Complexity: O(1)
Solution 2
Implementation
class Solution {
public int firstUniqChar(String s) {
int ans = Integer.MAX_VALUE;
for (char i = 'a'; i <= 'z';i++) {
int ind = s.indexOf (i);
if (ind != -1 && ind == s.lastIndexOf (i))
ans = Math.min (ans,ind);
}
if (ans == Integer.MAX_VALUE)
return -1;
return ans;
}
}
Solution 3
Using LinkedHashMap to find first non repeated character of String Algorithm : Step 1: get character array and loop through it to build a hash table with char and their count. Step 2: loop through LinkedHashMap to find an entry with value 1, that’s your first non-repeated character, as LinkedHashMap maintains insertion order.
Implementation
class Solution {
public static char getFirstNonRepeatedChar(String str) {
Map<Character,Integer> counts = new LinkedHashMap<>(str.length());
for (char c : str.toCharArray()) {
counts.put(c, counts.containsKey(c) ? counts.get(c) + 1 : 1);
}
for (Entry<Character,Integer> entry : counts.entrySet()) {
if (entry.getValue() == 1) {
return entry.getKey();
}
}
throw new RuntimeException("didn't find any non repeated Character");
}
}
String indexOf() custom method
Get index of first occurrance of second string in the first String using recursion
Implementation
class Solution {
public static int indexOf(String s1, String s2) {
if (s1.length() < s2.length()) {
return -1;
} else if (s1.substring(0, s2.length()).equals(s2)) {
return 0;
} else {
int i = indexOf(s1.substring(1, s1.length()), s2);
if (i == -1) {
return i;
} else {
return 1 + i;
}
}
}
}
Output:
String s1 = "BarackObama";
String s2 = "rac";
indexOf(s1, s2);
Complexity Analysis
Time Complexity:
Space Complexity:
Test
Implementation
Runtime
Memory
Complexity Analysis
Time Complexity:
Space Complexity:
Longest Substring Without Repeating Characters
Given a string s, find the length of the longest substring without repeating characters.
Example 1:
Input: s = "abcabcbb"
Output: 3
Explanation: The answer is "abc", with the length of 3.
Example 2:
Input: s = "bbbbb"
Output: 1
Explanation: The answer is "b", with the length of 1.
Example 3:
Input: s = "pwwkew"
Output: 3
Explanation: The answer is "wke", with the length of 3.
Notice that the answer must be a substring, "pwke" is a subsequence and not a substring.
Solution 1: Brute Force
Intuition
Check all the substring one by one to see if it has no duplicate character.
Algorithm
Suppose we have a function boolean allUnique(String substring) which will return true if the characters in the substring are all unique, otherwise false. We can iterate through all the possible substrings of the given string s and call the function allUnique. If it turns out to be true, then we update our answer of the maximum length of substring without duplicate characters.
Now let’s fill the missing parts:
To enumerate all substrings of a given string, we enumerate the start and end indices of them. Suppose the start and end indices are i and j, respectively. Then we have 0≤i<j≤n (here end index j is exclusive by convention). Thus, using two nested loops with i from 0 to n−1 and j from i+1 to n, we can enumerate all the substrings of s.
To check if one string has duplicate characters, we can use a set. We iterate through all the characters in the string and put them into the set one by one. Before putting one character, we check if the set already contains it. If so, we return false. After the loop, we return true.
Implementation
class Solution {
public class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length();
int res = 0;
for (int i = 0; i < n; i++) {
for (int j = i; j < n; j++) {
if (checkRepetition(s, i, j)) {
res = Math.max(res, j - i + 1);
}
}
}
return res;
}
private boolean checkRepetition(String s, int start, int end) {
int[] chars = new int[128];
for (int i = start; i <= end; i++) {
char c = s.charAt(i);
chars[c]++;
if (chars[c] > 1) {
return false;
}
}
return true;
}
}
}
Complexity Analysis

Solution 2: Sliding Window
Algorithm
The naive approach is very straightforward. But it is too slow. So how can we optimize it?
In the naive approaches, we repeatedly check a substring to see if it has duplicate character. But it is unnecessary. If a substring sij
from index i to j−1 is already checked to have no duplicate characters. We only need to check if s[j] is already in the substring sij .
To check if a character is already in the substring, we can scan the substring, which leads to an O(n^2) algorithm. But we can do better.
By using HashSet as a sliding window, checking if a character in the current can be done in O(1).
A sliding window is an abstract concept commonly used in array/string problems. A window is a range of elements in the array/string which usually defined by the start and end indices, i.e. [i,j) (left-closed, right-open). A sliding window is a window “slides” its two boundaries to the certain direction. For example, if we slide [i,j) to the right by 11 element, then it becomes [i+1,j+1) (left-closed, right-open).
Back to our problem. We use HashSet to store the characters in current window [i,j) (j=i initially). Then we slide the index j to the right. If it is not in the HashSet, we slide j further. Doing so until s[j] is already in the HashSet. At this point, we found the maximum size of substrings without duplicate characters start with index i. If we do this for all i, we get our answer.
Implementation
class Solution {
public class Solution {
public int lengthOfLongestSubstring(String s) {
int[] chars = new int[128];
int left = 0;
int right = 0;
int res = 0;
while (right < s.length()) {
char r = s.charAt(right);
chars[r]++;
while (chars[r] > 1) {
char l = s.charAt(left);
chars[l]--;
left++;
}
res = Math.max(res, right - left + 1);
right++;
}
return res;
}
}
}
solution 3: Sliding Window Optimized
The above solution requires at most 2n steps. In fact, it could be optimized to require only n steps. Instead of using a set to tell if a character exists or not, we could define a mapping of the characters to its index. Then we can skip the characters immediately when we found a repeated character.
The reason is that if s[j] have a duplicate in the range [i, j) with index j’,we don’t need to increase i little by little. We can skip all the elements in the range [i, j’] and let i to be j’ + 1 directly.
Java (Using HashMap)
Implementation
class Solution {
public class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length(), ans = 0;
Map<Character, Integer> map = new HashMap<>(); // current index of character
// try to extend the range [i, j]
for (int j = 0, i = 0; j < n; j++) {
if (map.containsKey(s.charAt(j))) {
i = Math.max(map.get(s.charAt(j)), i);
}
ans = Math.max(ans, j - i + 1);
map.put(s.charAt(j), j + 1);
}
return ans;
}
}
}
Java (Assuming ASCII 128)
The previous implements all have no assumption on the charset of the string s.
If we know that the charset is rather small, we can replace the Map with an integer array as direct access table.
Commonly used tables are:
int[26] for Letters ‘a’ - ‘z’ or ‘A’ - ‘Z’ int[128] for ASCII int[256] for Extended ASCII
Implementation
class Solution {
public class Solution {
public int lengthOfLongestSubstring(String s) {
Integer[] chars = new Integer[128];
int left = 0;
int right = 0;
int res = 0;
while (right < s.length()) {
char r = s.charAt(right);
Integer index = chars[r];
if (index != null && index >= left && index < right) {
left = index + 1;
}
res = Math.max(res, right - left + 1);
chars[r] = right;
right++;
}
return res;
}
}
}
Complexity Analysis
Time complexity : O(n). Index jj will iterate nn times.
Space complexity (HashMap) : O(min(m,n)). Same as the previous approach.
Space complexity (Table): O(m). m is the size of the charset.
Valid Parentheses
Given a string s containing just the characters '(', ')', '{', '}', '[' and ']', determine if the input string is valid.
An input string is valid if:
- Open brackets must be closed by the same type of brackets.
- Open brackets must be closed in the correct order.
- Every close bracket has a corresponding open bracket of the same type.
Example 1:
Input: s = "()"
Output: true
Example 2:
Input: s = "()[]{}"
Output: true
Example 3:
Input: s = "(]"
Output: false
Constraints:
1 <= s.length <= 104
s consists of parentheses only '()[]{}'.
Solution 1 : Stacks
Intuition
Imagine you are writing a small compiler for your college project and one of the tasks (or say sub-tasks) for the compiler would be to detect if the parenthesis are in place or not.
The algorithm we will look at in this article can be then used to process all the parenthesis in the program your compiler is compiling and checking if all the parenthesis are in place. This makes checking if a given string of parenthesis is valid or not, an important programming problem.
The expressions that we will deal with in this problem can consist of three different type of parenthesis:
(),
{} and
[]
Before looking at how we can check if a given expression consisting of these parenthesis is valid or not, let us look at a simpler version of the problem that consists of just one type of parenthesis. So, the expressions we can encounter in this simplified version of the problem are e.g.
(((((()))))) -- VALID
()()()() -- VALID
(((((((() -- INVALID
((()(()))) -- VALID
An interesting property about a valid parenthesis expression is that a sub-expression of a valid expression should also be a valid expression. (Not every sub-expression) e.g.
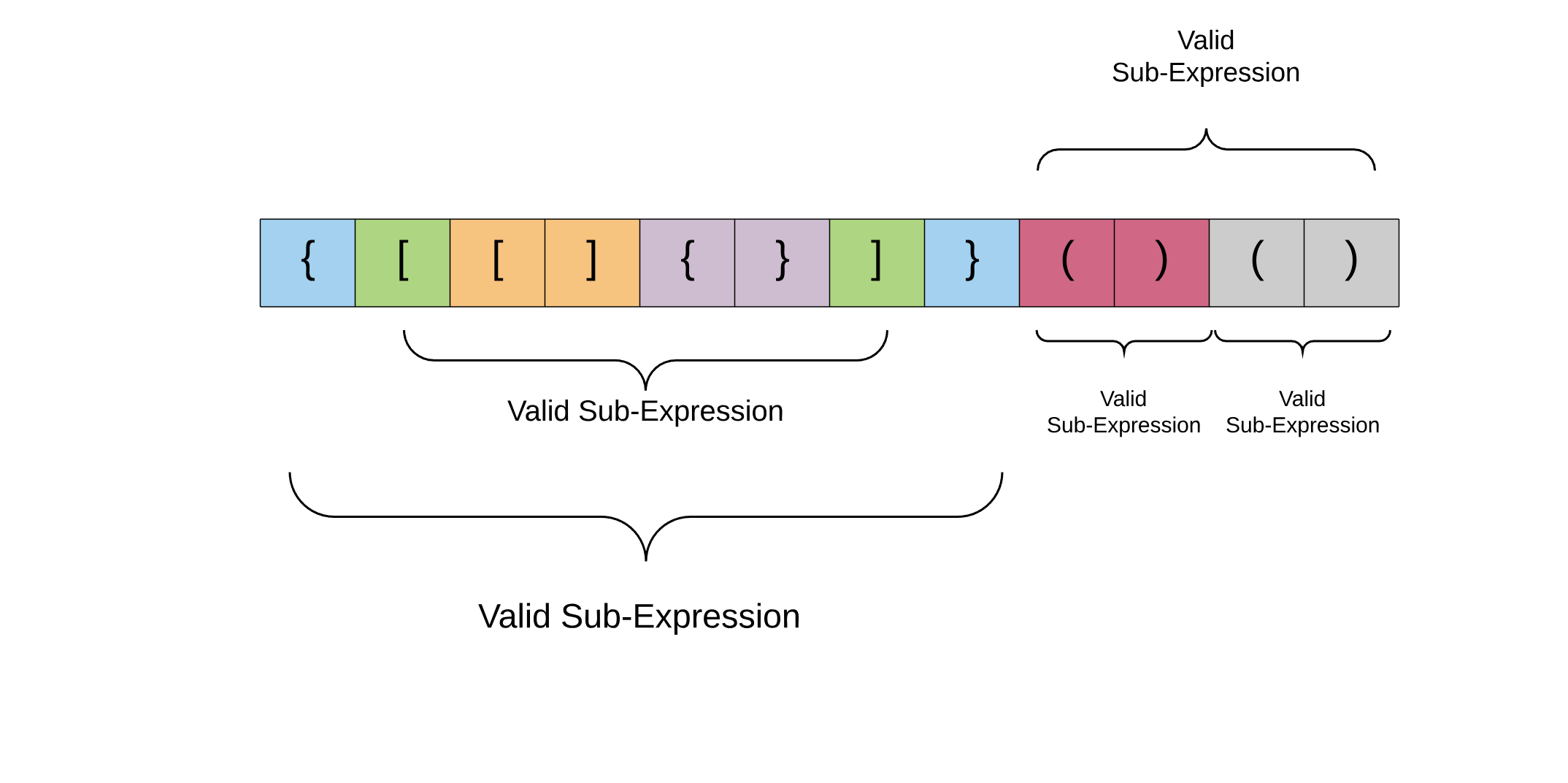
Also, if you look at the above structure carefully, the color coded cells mark the opening and closing pairs of parenthesis. The entire expression is valid, but sub portions of it are also valid in themselves. This lends a sort of a recursive structure to the problem. For e.g. Consider the expression enclosed within the two green parenthesis in the diagram above. The opening bracket at index 1 and the corresponding closing bracket at index 6.
Algorithm
- Initialize a stack S.
- Process each bracket of the expression one at a time.
- If we encounter an opening bracket, we simply push it onto the stack. This means we will process it later, let us simply move onto the sub-expression ahead.
- If we encounter a closing bracket, then we check the element on top of the stack. If the element at the top of the stack is an opening bracket of the same type, then we pop it off the stack and continue processing. Else, this implies an invalid expression.
- In the end, if we are left with a stack still having elements, then this implies an invalid expression.
class Solution {
// Hash table that takes care of the mappings.
private HashMap<Character, Character> mappings;
// Initialize hash map with mappings. This simply makes the code easier to read.
public Solution() {
this.mappings = new HashMap<Character, Character>();
this.mappings.put(')', '(');
this.mappings.put('}', '{');
this.mappings.put(']', '[');
}
public boolean isValid(String s) {
// Initialize a stack to be used in the algorithm.
Stack<Character> stack = new Stack<Character>();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
// If the current character is a closing bracket.
if (this.mappings.containsKey(c)) {
// Get the top element of the stack. If the stack is empty, set a dummy value of '#'
char topElement = stack.empty() ? '#' : stack.pop();
// If the mapping for this bracket doesn't match the stack's top element, return false.
if (topElement != this.mappings.get(c)) {
return false;
}
} else {
// If it was an opening bracket, push to the stack.
stack.push(c);
}
}
// If the stack still contains elements, then it is an invalid expression.
return stack.isEmpty();
}
}
Complexity analysis
Time complexity : O(n) because we simply traverse the given string one character at a time and push and pop operations on a stack take O(1) time.
Space complexity : O(n) as we push all opening brackets onto the stack and in the worst case, we will end up pushing all the brackets onto the stack. e.g. ((((((((((.
Solution 2 : Hashmap
class Solution {
public boolean isValid(String s) {
if(s.length()%2!=0)
return false;
HashMap<Character,Character> paren = new HashMap<>();
paren.put('(',')');
paren.put('[',']');
paren.put('{','}');
Stack<Character> stack = new Stack<>();
for (char ch: s.toCharArray()) {
if (paren.containsKey(ch))
{
stack.push(ch);
}
else if (stack.isEmpty() || paren.get(stack.pop()) != ch) {
return false;
}
}
return stack.isEmpty();
}
}
Solution 3 : Simple
Implementation
public class Solution {
public boolean isValid(String s) {
Stack<Character> stack = new Stack<>();
for(int i = 0; i < s.length(); i++) {
char a = s.charAt(i);
if(a == '(' || a == '[' || a == '{') stack.push(a);
else if(stack.empty()) return false;
else if(a == ')' && stack.pop() != '(') return false;
else if(a == ']' && stack.pop() != '[') return false;
else if(a == '}' && stack.pop() != '{') return false;
}
return stack.empty();
}
}
Add Strings
Given two non-negative integers, num1 and num2 represented as string, return the sum of num1 and num2 as a string.
You must solve the problem without using any built-in library for handling large integers (such as BigInteger). You must also not convert the inputs to integers directly.
Example 1:
Input: num1 = "11", num2 = "123"
Output: "134"
Example 2:
Input: num1 = "456", num2 = "77"
Output: "533"
Example 3:
Input: num1 = "0", num2 = "0"
Output: "0"
Constraints:
* 1 <= num1.length, num2.length <= 104
* num1 and num2 consist of only digits.
* num1 and num2 don't have any leading zeros except for the zero itself.
Solution 1 : StringBuilder
Algorithm
-
Initialize an empty res structure. Once could use StringBuilder in Java.
-
Start from carry = 0.
-
Set a pointer at the end of each string: p1 = num1.length() - 1, p2 = num2.length() - 1.
-
Loop over the strings from the end to the beginning using p1 and p2. Stop when both strings are used entirely.
-
Set x1 to be equal to a digit from string nums1 at index p1. If p1 has reached the beginning of nums1, set x1 to 0.
-
Do the same for x2. Set x2 to be equal to digit from string nums2 at index p2. If p2 has reached the beginning of nums2, set x2 to 0.
-
Compute the current value: value = (x1 + x2 + carry) % 10, and update the carry: carry = (x1 + x2 + carry) / 10.
-
Append the current value to the result: res.append(value).
-
-
Now both strings are done. If the carry is still non-zero, update the result: res.append(carry).
-
Reverse the result, convert it to a string, and return that string.
class Solution {
public String addStrings(String num1, String num2) {
StringBuilder res = new StringBuilder();
int carry = 0;
int p1 = num1.length() - 1;
int p2 = num2.length() - 1;
while (p1 >= 0 || p2 >= 0) {
int x1 = p1 >= 0 ? num1.charAt(p1) - '0' : 0;
int x2 = p2 >= 0 ? num2.charAt(p2) - '0' : 0;
int value = (x1 + x2 + carry) % 10;
carry = (x1 + x2 + carry) / 10;
res.append(value);
p1--;
p2--;
}
if (carry != 0)
res.append(carry);
return res.reverse().toString();
}
}
Complexity Analysis
Time Complexity: O(max(N_1,N_2)), where N_1 N_2 are length of nums1 and nums2. Here we do max(N_1, N_2) iterations at most.
Space Complexity: O(max(N_1,N_2)), because the length of the new string is at most max(N_1, N_2) + 1
Solution 2 : Simple
Algorithm
- Start iterating the strings from the end
- take each digit of the both strings
- add them up and
- place the result of sum at desired position in the char array
class Solution {
public String addStrings(String num1, String num2) {
int num1Len = num1.length() - 1;
int num2Len = num2.length() - 1;
int maxLen = Math.max(num1Len, num2Len) + 2;
char[] res = new char[maxLen];
int sum = 0;
while(num1Len >= 0 || num2Len >= 0) {
if(num1Len >= 0) {
sum += num1.charAt(num1Len--) - '0';
}
if(num2Len >= 0) {
sum += num2.charAt(num2Len--) - '0';
}
res[--maxLen] = (char)((sum % 10) + '0');
sum /= 10;
}
if(sum != 0) {
res[0] = '1';
return String.valueOf(res);
}
return String.valueOf(res, 1, res.length - 1);
}
}
Complexity Analysis
Time: O(max(m, n)), where m and n are the lengths of given Strings a and b respectively.
Space: O(max(m, n)), as we need a char array(res) whose size is equal to max of length of 2 input strings
Valid Anagram
Given two strings s and t, return true if t is an anagram of s, and false otherwise.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
Example 1:
Input: s = "anagram", t = "nagaram"
Output: true
Example 2:
Input: s = "rat", t = "car"
Output: false
Constraints:
* 1 <= s.length, t.length <= 5 * 104
* s and t consist of lowercase English letters.
Solution 1 : Sorting
Algorithm
An anagram is produced by rearranging the letters of s into t. Therefore, if t is an anagram of s, sorting both strings will result in two identical strings. Furthermore, if ss and t have different lengths, t must not be an anagram of s and we can return early.
class Solution {
public boolean isAnagram(String s, String t) {
if (s.length() != t.length()) {
return false;
}
char[] str1 = s.toCharArray();
char[] str2 = t.toCharArray();
Arrays.sort(str1);
Arrays.sort(str2);
return Arrays.equals(str1, str2);
}
}
Complexity Analysis
Time complexity: O(nlogn). Assume that n is the length of s, sorting costs O(nlogn) and comparing two strings costs O(n). Sorting time dominates and the overall time complexity is O(nlogn).
Space complexity: O(1). Space depends on the sorting implementation which, usually, costs O(1) auxiliary space if heapsort is used. Note that in Java, toCharArray() makes a copy of the string so it costs O(n) extra space, but we ignore this for complexity analysis because:
-
It is a language dependent detail.
-
It depends on how the function is designed. For example, the function parameter types can be changed to char[].
Solution 2 : Frequency Counter
Algorithm
To examine if t is a rearrangement of s, we can count occurrences of each letter in the two strings and compare them. We could use a hash table to count the frequency of each letter, however, since both s and t only contain letters from a to z, a simple array of size 26 will suffice.
Do we need two counters for comparison? Actually no, because we can increment the count for each letter in s and decrement the count for each letter in t, and then check if the count for every character is zero.
class Solution {
public boolean isAnagram(String s, String t) {
if (s.length() != t.length()) {
return false;
}
int[] counter = new int[26];
for (int i = 0; i < s.length(); i++) {
counter[s.charAt(i) - 'a']++;
counter[t.charAt(i) - 'a']--;
}
for (int count : counter) {
if (count != 0) {
return false;
}
}
return true;
}
}
Or we could first increment the counter for s, then decrement the counter for t. If at any point the counter drops below zero, we know that t contains an extra letter not in s and return false immediately.
class Solution {
public boolean isAnagram(String s, String t) {
if (s.length() != t.length()) {
return false;
}
int[] table = new int[26];
for (int i = 0; i < s.length(); i++) {
table[s.charAt(i) - 'a']++;
}
for (int i = 0; i < t.length(); i++) {
table[t.charAt(i) - 'a']--;
if (table[t.charAt(i) - 'a'] < 0) {
return false;
}
}
return true;
}
}
Complexity Analysis
Time complexity: O(n). Time complexity is O(n) because accessing the counter table is a constant time operation.
Space complexity: O(1). Although we do use extra space, the space complexity is O(1) because the table’s size stays constant no matter how large n is.
Solution 3 : Simple
class Solution {
public boolean isAnagram(String s, String t) {
int[] charsMap = new int['z' - 'a' + 1];
for (char c : s.toCharArray()) {
int pos = c - 'a';
charsMap[pos]++;
}
for (char c : t.toCharArray()) {
int pos = c - 'a';
charsMap[pos]--;
}
for (int count : charsMap) {
if (count != 0) {
return false;
}
}
return true;
}
}
Solution 4 : 3m fastest java solution
Implementation
class Solution {
public boolean isAnagram(String s, String t) {
int length = s.length();
if(length != t.length()) {
return false;
}
char[] str_s = s.toCharArray();
char[] str_t = t.toCharArray();
int[] mask = new int[256];
for(char c : str_s) {
mask[c]++;
}
for(char c : str_t) {
if(mask[c] > 0) {
mask[c]--;
} else {
return false;
}
}
return true;
}
}
Group Anagrams
Given an array of strings strs, group the anagrams together. You can return the answer in any order.
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
Example 1:
Input: strs = ["eat","tea","tan","ate","nat","bat"]
Output: [["bat"],["nat","tan"],["ate","eat","tea"]]
Example 2:
Input: strs = [""]
Output: [[""]]
Example 3:
Input: strs = ["a"]
Output: [["a"]]
Constraints:
1 <= strs.length <= 104
0 <= strs[i].length <= 100
strs[i] consists of lowercase English letters.
Solution 1 : Categorize by Sorted String
Intuition
Two strings are anagrams if and only if their sorted strings are equal.
Algorithm
Maintain a map ans : {String -> List} where each key K is a sorted string, and each value is the list of strings from the initial input that when sorted, are equal to K.
In Java, we will store the key as a string, eg. code. In Python, we will store the key as a hashable tuple, eg. ('c', 'o', 'd', 'e').

Implementation
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
if (strs.length == 0) return new ArrayList();
Map<String, List> ans = new HashMap<String, List>();
for (String s : strs) {
char[] ca = s.toCharArray();
Arrays.sort(ca);
String key = String.valueOf(ca);
if (!ans.containsKey(key)) ans.put(key, new ArrayList());
ans.get(key).add(s);
}
return new ArrayList(ans.values());
}
}
Complexity Analysis
Time Complexity: O(NKlogK), where N is the length of strs, and K is the maximum length of a string in strs. The outer loop has complexity O(N) as we iterate through each string. Then, we sort each string in O(KlogK) time.
Space Complexity: O(NK), the total information content stored in ans.
Solution 2 : Categorize by Count
Intuition
Two strings are anagrams if and only if their character counts (respective number of occurrences of each character) are the same.
Algorithm
We can transform each string s into a character count, count, consisting of 26 non-negative integers representing the number of a’s, b’s, c’s, etc. We use these counts as the basis for our hash map.
In Java, the hashable representation of our count will be a string delimited with ‘#’ characters. For example, abbccc will be #1#2#3#0#0#0...#0 where there are 26 entries total.

Implemention
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
if (strs.length == 0) return new ArrayList();
Map<String, List> ans = new HashMap<String, List>();
int[] count = new int[26];
for (String s : strs) {
Arrays.fill(count, 0);
for (char c : s.toCharArray()) count[c - 'a']++;
StringBuilder sb = new StringBuilder("");
for (int i = 0; i < 26; i++) {
sb.append('#');
sb.append(count[i]);
}
String key = sb.toString();
if (!ans.containsKey(key)) ans.put(key, new ArrayList());
ans.get(key).add(s);
}
return new ArrayList(ans.values());
}
}
Complexity Analysis
Time Complexity: O(NK), where N is the length of strs, and K is the maximum length of a string in strs. Counting each string is linear in the size of the string, and we count every string.
Space Complexity: O(NK), the total information content stored in ans.
Solution 3 : Simple Java Solution Beats 99.05% 5ms
Implementation
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
HashMap<String,List<String>> map=new HashMap<>();
for(int i=0;i<strs.length;i++){
String s1=strs[i];
char[] arr=s1.toCharArray();
Arrays.sort(arr);
String str=new String(arr);
if(map.containsKey(str)){
map.get(str).add(s1);
}else{
map.put(str,new ArrayList<>());
map.get(str).add(s1);
}
}
return new ArrayList<>(map.values());
}
}
Complexity Analysis
Time Complexity: O(n * klog(k)) since we are sorting k characters n times in the loop.
Solution 4 :
Implementation
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
if (strs == null || strs.length == 0) return new ArrayList<>();
Map<String, List<String>> map = new HashMap<>();
for (String s : strs) {
char[] ca = s.toCharArray();
Arrays.sort(ca);
String keyStr = String.valueOf(ca);
if (!map.containsKey(keyStr)) map.put(keyStr, new ArrayList<>());
map.get(keyStr).add(s);
}
return new ArrayList<>(map.values());
}
}
Instead of sorting, we can also build the key string in this way.
class Solution {
public List<List<String>> groupAnagrams(String[] strs) {
if (strs == null || strs.length == 0) return new ArrayList<>();
Map<String, List<String>> map = new HashMap<>();
for (String s : strs) {
char[] ca = new char[26];
for (char c : s.toCharArray()) ca[c - 'a']++;
String keyStr = String.valueOf(ca);
if (!map.containsKey(keyStr)) map.put(keyStr, new ArrayList<>());
map.get(keyStr).add(s);
}
return new ArrayList<>(map.values());
}
}
Find the Difference
You are given two strings s and t.
String t is generated by random shuffling string s and then add one more letter at a random position.
Return the letter that was added to t.
Example 1:
Input: s = "abcd", t = "abcde"
Output: "e"
Explanation: 'e' is the letter that was added.
Example 2:
Input: s = "", t = "y"
Output: "y"
Constraints:
0 <= s.length <= 1000
t.length == s.length + 1
s and t consist of lowercase English letters.
Solution 1 : Sorting
Intuition
The obvious choice is sorting. Why obvious?
It’s obvious because the first thing we might think of is, what if string t was not shuffled. If string t was not shuffled this problem would have been so easy.
And then next we might end up bringing the order between the two strings. What better than sorting both the strings.
i.e. sort(String t) = sort(shuffled(String s + Any character)).
That said, this could be one of the most brute ways of solving this problem. (There are other brute ways too. The intent is not to challenge your brute instincts :P)
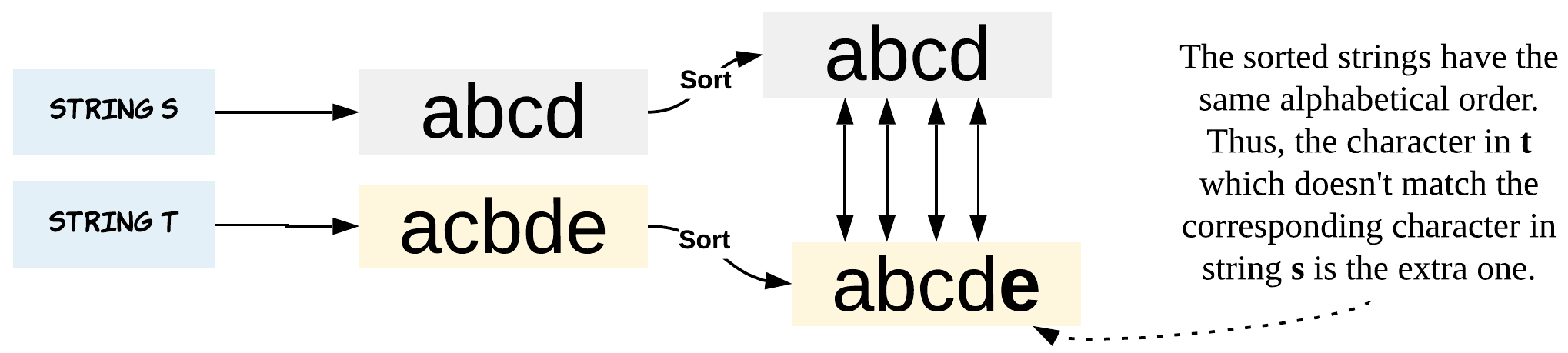
Have you played Spot the Difference games, where you match an orange to orange and rule out the possibility? That’s exactly what we are doing after sorting the strings.
Algorithm
-
Sort the string s and string t.
-
Iterate through the length of strings and do a character by character comparison. This just checks if the current character in string t is present in string s.
-
Once we encounter a character which is in string t but not in string s, we have found the extra character string t was hiding all this while.
Implementation
class Solution {
public char findTheDifference(String s, String t) {
// Sort both the strings
char[] sortedS = s.toCharArray();
char[] sortedT = t.toCharArray();
Arrays.sort(sortedS);
Arrays.sort(sortedT);
// Character by character comparison
int i = 0;
while (i < s.length()) {
if (sortedS[i] != sortedT[i]) {
return sortedT[i];
}
i += 1;
}
return sortedT[i];
}
}
Complexity Analysis
Time Complexity: O(Nlog(N)), where N is length of the strings. Sorting is the most expensive operation of this algorithm. Sorting would take O(Nlog(N)) time. Iterating both the strings for character by character comparison would take another O(N) time.
Space Complexity: O(N). The sorted character arrays would take O(N) each. An important thing to note here is that we are converting the String in java to an array first and then sorting it. That’s what takes the additional space.
Solution 2 : Using HashMap
This approach is also not very tricky. What is important is to analyze its complexity.
We might just think in worst case the string is of length N and each character has a frequency of 1. This would result in a hash map of O(N) space. This is when your attention to detail comes to test.
The problem states, string s and t consists of only lowercase letters.
The above statement implies we only have 26 characters i.e. [a, z]. Thus, we have a space complexity for just 26 characters.
It’s always good to clarify this with the interviewer as now the space complexity would just be constant. Thus, this approach can also be implemented using array of length 26 as a hash table, where each index corresponds to a letter from [a, z].
Algorithm
-
Store all the characters of string
sin a hash map calledcounterS. The key would be the character and value would be number of times the character appeared in the string. -
Now, iterate through string
tand for each character, check if it is present in the hash mapcounterS. -
If the character is present in
counterSthen we just decrement the corresponding value by1. -
If the character is not present in
counterSor has a frequency of zero in counterS it means we have found the extra character of stringt.
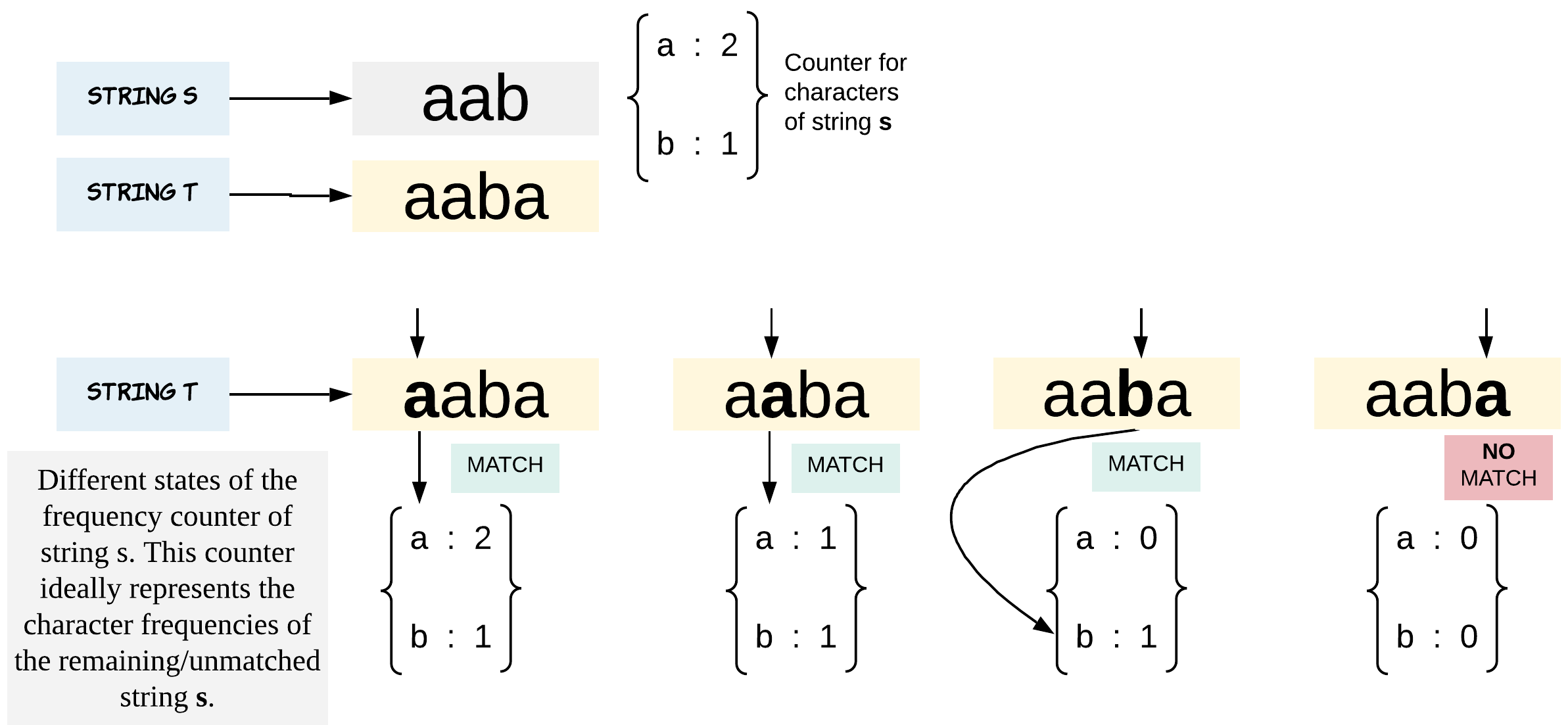
Note - We are dropping the frequency of a character by 1 every time there is a match. This helps us find out the extra character which is present in both s and t but the number of occurrences vary. Thus keeping frequency is equally important.
Implementation
class Solution {
public char findTheDifference(String s, String t) {
char extraChar = '\0';
// Prepare a counter for string s.
// This hash map holds the characters as keys and respective frequency as value.
HashMap <Character,Integer> counterS = new HashMap <>();
for (int i = 0; i < s.length(); i++) {
char ch = s.charAt(i);
counterS.put(ch, counterS.getOrDefault(ch, 0) + 1);
}
// Iterate through string t and find the character which is not in s.
for (int i = 0; i < t.length(); i += 1) {
char ch = t.charAt(i);
int countOfChar = counterS.getOrDefault(ch, 0);
if (countOfChar == 0) {
extraChar = ch;
break;
} else {
// Once a match is found we reduce frequency left.
// This eliminates the possibility of a false match later.
counterS.put(ch, countOfChar - 1);
}
}
return extraChar;
}
}
Complexity Analysis
Time Complexity: O(N), where N is length of the strings. Since, we iterate through both the strings once.
Space Complexity: O(1). The problem states string s and string t have lowercase letters. Thus, the total number of unique characters and eventually buckets in the hash map possible are just 26.
Solution 3 : Bit Manipulation
Don’t be scared. This approach is as simple as scary it might sound.
The trick is simple. To use bitwise XOR operation on all the elements. XOR would help to eliminate the alike and only leave the odd duckling.
To understand how this works, let’s brush up our XOR concepts first.
0 ^ 0 = 0
0 ^ 1 = 1
1 ^ 0 = 1
1 ^ 1 = 0
Look at how the similar ones just even out. This is what we would use to our advantage. When all the other similar pairs just even out or reduce to a zero, the different one would remain.
Thus, the left over bits after XORing all the characters from string s and string t would be from the extra character of string t.
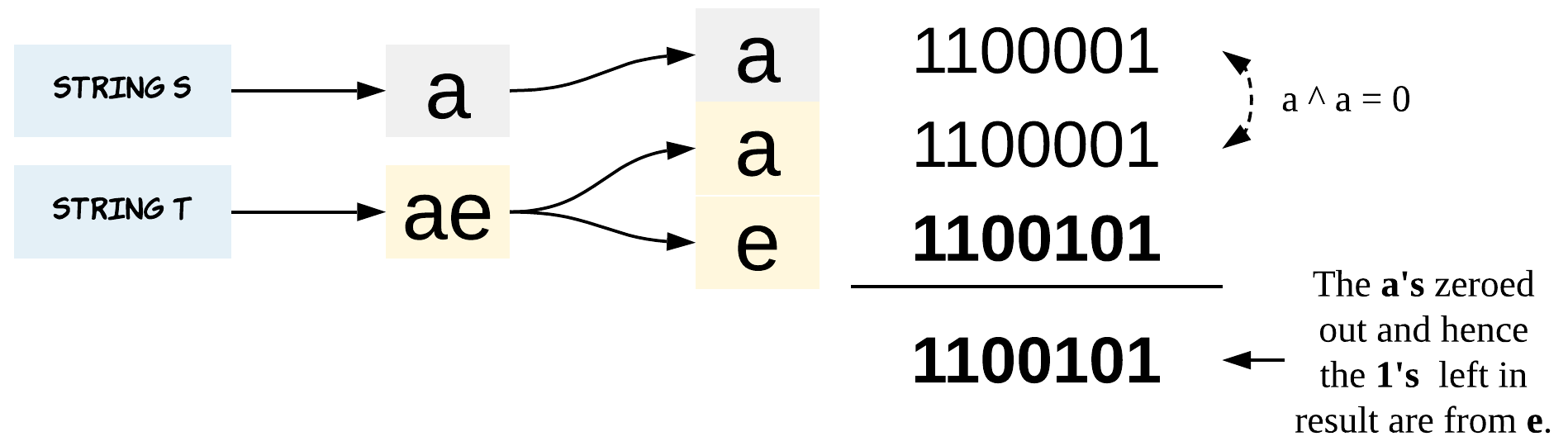
Algorithm
-
Initialize a variable
chwhich would hold theXORed results. -
XORall the characters withchwhile iterating through strings. -
XORall the characters withchwhile iterating through stringt. (Alternatively, we could have also combined steps 2 and 3). -
Return
chas the answer.
Implementation
class Solution {
public char findTheDifference(String s, String t) {
// Initialize ch with 0, because 0 ^ X = X
// 0 when XORed with any bit would not change the bits value.
char ch = 0;
// XOR all the characters of both s and t.
for (int i = 0; i < s.length(); i += 1) {
ch ^= s.charAt(i);
}
for (int i = 0; i < t.length(); i += 1) {
ch ^= t.charAt(i);
}
// What is left after XORing everything is the difference.
return ch;
}
}
Complexity Analysis
Time Complexity: O(N), where N is length of the strings. Since, we iterate through both the strings once.
Space Complexity: O(1).
Solution 4 : Using array as a map
Implementation
class Solution {
var count = new short[26];
for (int i=0; i<s.length(); i++) {
count[s.charAt(i) - 'a']++;
count[t.charAt(i) - 'a']--;
}
count[t.charAt(t.length() - 1) - 'a']--; // since t.length() = s.length() + 1
for (int i=0; i<count.length; i++) {
if (count[i] < 0) {
return (char)('a' + i);
}
}
return (char)0;
Solution 5 : Two very easy solutions
Implementation 1
class Solution {
public char findTheDifference(String s, String t) {
int result = 0;
for (int i = 0; i < s.length(); i++) {
//char - char the result is int
result += t.charAt(i) - s.charAt(i);
}
//use ASCII table to get the letter
return (char) (result + t.charAt(t.length() - 1));
}
}
Implementation 2
class Solution {
public char findTheDifference(String s, String t) {
int result = 0;
for (int i = 0; i < s.length(); i++) {
//use XOR,just like question 136
result ^= s.charAt(i);
result ^= t.charAt(i);
}
return (char) (result ^ t.charAt(t.length() - 1));
}
}
Valid Parenthesis String
Given a string s containing only three types of characters: '(', ')' and '*', return true if s is valid.
The following rules define a valid string:
-
Any left parenthesis
'('must have a corresponding right parenthesis')'. -
Any right parenthesis
')'must have a corresponding left parenthesis'('. -
Left parenthesis
'('must go before the corresponding right parenthesis')'. -
'*'could be treated as a single right parenthesis')'or a single left parenthesis'('or an empty string"".
Example 1:
Input: s = "()"
Output: true
Example 2:
Input: s = "(*)"
Output: true
Example 3:
Input: s = "(*))"
Output: true
Constraints:
1 <= s.length <= 100
s[i] is '(', ')' or '*'.
Solution 1 : Brute Force [Time Limit Exceeded]
Intuition and Algorithm
For each asterisk, let’s try both possibilities.
class Solution {
boolean ans = false;
public boolean checkValidString(String s) {
solve(new StringBuilder(s), 0);
return ans;
}
public void solve(StringBuilder sb, int i) {
if (i == sb.length()) {
ans |= valid(sb);
} else if (sb.charAt(i) == '*') {
for (char c: "() ".toCharArray()) {
sb.setCharAt(i, c);
solve(sb, i+1);
if (ans) return;
}
sb.setCharAt(i, '*');
} else
solve(sb, i + 1);
}
public boolean valid(StringBuilder sb) {
int bal = 0;
for (int i = 0; i < sb.length(); i++) {
char c = sb.charAt(i);
if (c == '(') bal++;
if (c == ')') bal--;
if (bal < 0) break;
}
return bal == 0;
}
}
Complexity Analysis
Time Complexity: O(N * 3^{N}), where N is the length of the string. For each asterisk we try 3 different values. Thus, we could be checking the validity of up to 3^N strings. Then, each check of validity is O(N).
Space Complexity: O(N), the space used by our character array.
Solution 2 : Dynamic Programming [Accepted]
Intuition and Algorithm
Let dp[i][j] be true if and only if the interval s[i], s[i+1], ..., s[j] can be made valid. Then dp[i][j] is true only if:
s[i] is '*', and the interval s[i+1], s[i+2], ..., s[j] can be made valid;
or, s[i] can be made to be '(', and there is some k in [i+1, j] such that s[k] can be made to be ')', plus the two intervals cut by s[k] (s[i+1: k] and s[k+1: j+1]) can be made valid;
class Solution {
public boolean checkValidString(String s) {
int n = s.length();
if (n == 0) return true;
boolean[][] dp = new boolean[n][n];
for (int i = 0; i < n; i++) {
if (s.charAt(i) == '*') dp[i][i] = true;
if (i < n-1 &&
(s.charAt(i) == '(' || s.charAt(i) == '*') &&
(s.charAt(i+1) == ')' || s.charAt(i+1) == '*')) {
dp[i][i+1] = true;
}
}
for (int size = 2; size < n; size++) {
for (int i = 0; i + size < n; i++) {
if (s.charAt(i) == '*' && dp[i+1][i+size] == true) {
dp[i][i+size] = true;
} else if (s.charAt(i) == '(' || s.charAt(i) == '*') {
for (int k = i+1; k <= i+size; k++) {
if ((s.charAt(k) == ')' || s.charAt(k) == '*') &&
(k == i+1 || dp[i+1][k-1]) &&
(k == i+size || dp[k+1][i+size])) {
dp[i][i+size] = true;
}
}
}
}
}
return dp[0][n-1];
}
}
Complexity Analysis
Time Complexity: O(N^3), where N is the length of the string. There are O(N^2) states corresponding to entries of dp, and we do an average of O(N) work on each state.
Space Complexity: O(N^2), the space used to store intermediate results in dp.
Solution 3 : Greedy [Accepted]
Intuition
When checking whether the string is valid, we only cared about the “balance”: the number of extra, open left brackets as we parsed through the string. For example, when checking whether '(()())' is valid, we had a balance of 1, 2, 1, 2, 1, 0 as we parse through the string: '(' has 1 left bracket, '((' has 2, '(()' has 1, and so on. This means that after parsing the first i symbols, (which may include asterisks,) we only need to keep track of what the balance could be.
For example, if we have string '(***)', then as we parse each symbol, the set of possible values for the balance is [1] for '('; [0, 1, 2] for '(*'; [0, 1, 2, 3] for '(**'; [0, 1, 2, 3, 4] for '(***', and [0, 1, 2, 3] for '(***)'.
Furthermore, we can prove these states always form a contiguous interval. Thus, we only need to know the left and right bounds of this interval. That is, we would keep those intermediate states described above as [lo, hi] = [1, 1], [0, 2], [0, 3], [0, 4], [0, 3].
Algorithm
Let lo, hi respectively be the smallest and largest possible number of open left brackets after processing the current character in the string.
If we encounter a left bracket (c == '('), then lo++, otherwise we could write a right bracket, so lo--. If we encounter what can be a left bracket (c != ')'), then hi++, otherwise we must write a right bracket, so hi--. If hi < 0, then the current prefix can’t be made valid no matter what our choices are. Also, we can never have less than 0 open left brackets. At the end, we should check that we can have exactly 0 open left brackets.
class Solution {
public boolean checkValidString(String s) {
int lo = 0, hi = 0;
for (char c: s.toCharArray()) {
lo += c == '(' ? 1 : -1;
hi += c != ')' ? 1 : -1;
if (hi < 0) break;
lo = Math.max(lo, 0);
}
return lo == 0;
}
}
Complexity Analysis
Time Complexity: O(N), where N is the length of the string. We iterate through the string once.
Space Complexity: O(1), the space used by our lo and hi pointers. However, creating a new character array will take O(N) space.
Remove Invalid Parentheses
Given a string s that contains parentheses and letters, remove the minimum number of invalid parentheses to make the input string valid.
Return all the possible results. You may return the answer in any order.
Example 1:
Input: s = "()())()"
Output: ["(())()","()()()"]
Example 2:
Input: s = "(a)())()"
Output: ["(a())()","(a)()()"]
Example 3:
Input: s = ")("
Output: [""]
Constraints:
1 <= s.length <= 25
s consists of lowercase English letters and parentheses '(' and ')'.
There will be at most 20 parentheses in s.
Solution 1 : Backtracking
Algorithm
-
Initialize an array that will store all of our valid expressions finally.
-
Start with the leftmost bracket in the given sequence and proceed right in the recursion.
-
The state of recursion is defined by the index which we are currently processing in the original expression. Let this index be represented by the character i. Also, we have two different variables
left_countandright_countthat represent the number of left and right parentheses we have added to our expression till now. These are the parentheses that were considered. -
If the current character i.e.
S[i](considering S is the expression string) is neither a closing or an opening parenthesis, then we simply add this character to our final solution string for the current recursion. -
However, if the current character is either of the two brackets i.e.
S[i] == '(' or S[i] == ')', then we have two options. We can either discard this character by marking it an invalid character or we can consider this bracket to be a part of the final expression. -
When all of the parentheses in the original expression have been processed, we simply check if the expression represented by expr i.e. the expression formed till now is valid one or not. The way we check if the final expression is valid or not is by looking at the values in
left_countandright_count. For an expression to be validleft_count == right_count. If it is indeed valid, then it could be one of our possible solutions.-
Even though we have a valid expression, we also need to keep track of the number of removals we did to get this expression. This is done by another variable passed in recursion called
rem_count. -
Once recursion finishes we check if the current value of
rem_countis < the least number of steps we took to form a valid expression till now i.e. the global minima. If this is not the case, we don’t record the new expression, else we record it.
-
One small optimization that we can do from an implementation perspective is introducing some sort of pruning in our algorithm. Right now we simply go till the very end i.e. process all of the parentheses and when we are done processing all of them, we check if the expression we have can be considered or not.
We have to wait till the very end to decide if the expression formed in recursion is a valid expression or not. Is there a way for us to cutoff from some of the recursion paths early on because they wouldn’t lead to a solution? The answer to this is Yes! The optimization is based on the following idea.
For a left bracket encountered during recursion, if we decide to consider it, then it may or may not lead to an invalid final expression. It may lead to an invalid expression eventually if there are no matching closing bracket available afterwards. But, we don’t know for sure if this will happen or not.
However, for a closing bracket, if we decide to keep it as a part of our final expression (remember for every bracket we have two options, either to keep it or to remove it and recurse further) and there is no corresponding opening bracket to match it in the expression till now, then it will definitely lead to an invalid expression no matter what we do afterwards.
e.g.
( ( ) ) )
In this case the third closing bracket will make the expression invalid. No matter what comes afterwards, this will give us an invalid expression and if such a thing happens, we shouldn’t recurse further and simply prune the recursion tree.
That is why, in addition to having the index in the original string/expression which we are currently processing and the expression string formed till now, we also keep track of the number of left and right parentheses. Whenever we keep a left parenthesis in the expression, we increment its counter. For a right parenthesis, we check if right_count < left_count. If this is the case then only we consider that right parenthesis and recurse further. Otherwise we don’t as we know it will make the expression invalid. This simple optimization saves a lot of runtime.
Now, let us look at the implementation for this algorithm.
class Solution {
private Set<String> validExpressions = new HashSet<String>();
private int minimumRemoved;
private void reset() {
this.validExpressions.clear();
this.minimumRemoved = Integer.MAX_VALUE;
}
private void recurse(
String s,
int index,
int leftCount,
int rightCount,
StringBuilder expression,
int removedCount) {
// If we have reached the end of string.
if (index == s.length()) {
// If the current expression is valid.
if (leftCount == rightCount) {
// If the current count of removed parentheses is <= the current minimum count
if (removedCount <= this.minimumRemoved) {
// Convert StringBuilder to a String. This is an expensive operation.
// So we only perform this when needed.
String possibleAnswer = expression.toString();
// If the current count beats the overall minimum we have till now
if (removedCount < this.minimumRemoved) {
this.validExpressions.clear();
this.minimumRemoved = removedCount;
}
this.validExpressions.add(possibleAnswer);
}
}
} else {
char currentCharacter = s.charAt(index);
int length = expression.length();
// If the current character is neither an opening bracket nor a closing one,
// simply recurse further by adding it to the expression StringBuilder
if (currentCharacter != '(' && currentCharacter != ')') {
expression.append(currentCharacter);
this.recurse(s, index + 1, leftCount, rightCount, expression, removedCount);
expression.deleteCharAt(length);
} else {
// Recursion where we delete the current character and move forward
this.recurse(s, index + 1, leftCount, rightCount, expression, removedCount + 1);
expression.append(currentCharacter);
// If it's an opening parenthesis, consider it and recurse
if (currentCharacter == '(') {
this.recurse(s, index + 1, leftCount + 1, rightCount, expression, removedCount);
} else if (rightCount < leftCount) {
// For a closing parenthesis, only recurse if right < left
this.recurse(s, index + 1, leftCount, rightCount + 1, expression, removedCount);
}
// Undoing the append operation for other recursions.
expression.deleteCharAt(length);
}
}
}
public List<String> removeInvalidParentheses(String s) {
this.reset();
this.recurse(s, 0, 0, 0, new StringBuilder(), 0);
return new ArrayList(this.validExpressions);
}
}
Complexity analysis
Time Complexity : O(2^N) since in the worst case we will have only left parentheses in the expression and for every bracket we will have two options i.e. whether to remove it or consider it. Considering that the expression has N parentheses, the time complexity will be O(2^N).
Space Complexity : O(N) because we are resorting to a recursive solution and for a recursive solution there is always stack space used as internal function states are saved onto a stack during recursion. The maximum depth of recursion decides the stack space used. Since we process one character at a time and the base case for the recursion is when we have processed all of the characters of the expression string, the size of the stack would be O(N). Note that we are not considering the space required to store the valid expressions. We only count the intermediate space here.
Solution 2 : Limited Backtracking!
Algorithm
The overall algorithm remains exactly the same as before. The changes that we will incorporate are listed below:
- The state of the recursion is now defined by five different variables:
-
index which represents the current character that we have to process in the original string.
-
left_countwhich represents the number of left parentheses that have been added to the expression we are building. -
right_countwhich represents the number of right parentheses that have been added to the expression we are building. -
left_remis the number of left parentheses that remain to be removed. -
right_remrepresents the number of right parentheses that remain to be removed. Overall, for the final expression to be valid,left_rem == 0andright_rem == 0.
-
-
When we decide to not consider a parenthesis i.e. delete a parenthesis, be it a left or a right parentheses, we have to consider their corresponding remaining counts as well. This means that we can only discard a left parentheses if
left_rem > 0and similarly for the right one we will check forright_rem > 0. -
There are no changes to checks for considering a parenthesis. Only the conditions change for discarding a parenthesis.
-
Condition for an expression being valid in the base case would now become
left_rem == 0andright_rem == 0. Note that we don’t have to check ifleft_count == right_countanymore because in the case of a valid expression, we would have removed all the misplaced or invalid parenthesis by the time the recursion ends. So, the only check we need ifleft_rem == 0andright_rem == 0.The most important thing here is that we have completely gotten rid of checking if the number of parentheses removed is lesser than the current minimum or not. The reason for this is we always remove the same number of parentheses as defined by left_rem + right_rem at the start of recursion.
Implementation
class Solution {
private Set<String> validExpressions = new HashSet<String>();
private void recurse(
String s,
int index,
int leftCount,
int rightCount,
int leftRem,
int rightRem,
StringBuilder expression) {
// If we reached the end of the string, just check if the resulting expression is
// valid or not and also if we have removed the total number of left and right
// parentheses that we should have removed.
if (index == s.length()) {
if (leftRem == 0 && rightRem == 0) {
this.validExpressions.add(expression.toString());
}
} else {
char character = s.charAt(index);
int length = expression.length();
// The discard case. Note that here we have our pruning condition.
// We don't recurse if the remaining count for that parenthesis is == 0.
if ((character == '(' && leftRem > 0) || (character == ')' && rightRem > 0)) {
this.recurse(
s,
index + 1,
leftCount,
rightCount,
leftRem - (character == '(' ? 1 : 0),
rightRem - (character == ')' ? 1 : 0),
expression);
}
expression.append(character);
// Simply recurse one step further if the current character is not a parenthesis.
if (character != '(' && character != ')') {
this.recurse(s, index + 1, leftCount, rightCount, leftRem, rightRem, expression);
} else if (character == '(') {
// Consider an opening bracket.
this.recurse(s, index + 1, leftCount + 1, rightCount, leftRem, rightRem, expression);
} else if (rightCount < leftCount) {
// Consider a closing bracket.
this.recurse(s, index + 1, leftCount, rightCount + 1, leftRem, rightRem, expression);
}
// Delete for backtracking.
expression.deleteCharAt(length);
}
}
public List<String> removeInvalidParentheses(String s) {
int left = 0, right = 0;
// First, we find out the number of misplaced left and right parentheses.
for (int i = 0; i < s.length(); i++) {
// Simply record the left one.
if (s.charAt(i) == '(') {
left++;
} else if (s.charAt(i) == ')') {
// If we don't have a matching left, then this is a misplaced right, record it.
right = left == 0 ? right + 1 : right;
// Decrement count of left parentheses because we have found a right
// which CAN be a matching one for a left.
left = left > 0 ? left - 1 : left;
}
}
this.recurse(s, 0, 0, 0, left, right, new StringBuilder());
return new ArrayList<String>(this.validExpressions);
}
}
Complexity analysis
Time Complexity : The optimization that we have performed is simply a better form of pruning. Pruning here is something that will vary from one test case to another. In the worst case, we can have something like ((((((((( and the left_rem = len(S) and in such a case we can discard all of the characters because all are misplaced. So, in the worst case we still have 2 options per parenthesis and that gives us a complexity of O(2^N).
Space Complexity : The space complexity remains the same i.e. O(N) as previous solution. We have to go to a maximum recursion depth of N before hitting the base case. Note that we are not considering the space required to store the valid expressions. We only count the intermediate space here.
Solution 3 : Optimized Backtracking
Implementation
class Solution {
public List<String> removeInvalidParentheses(String s) {
List<String> ans=new ArrayList<>();
HashSet<String> set=new HashSet<String>();
int minBracket=removeBracket(s);
getAns(s, minBracket,set,ans);
return ans;
}
public void getAns(String s, int minBracket, HashSet<String> set, List<String> ans){
if(set.contains(s)) return;
set.add(s);
if(minBracket==0){
int remove=removeBracket(s);
if(remove==0) ans.add(s);
return;
}
for(int i=0;i<s.length();i++){
if(s.charAt(i)!='(' && s.charAt(i)!=')') continue;
String L=s.substring(0,i);
String R=s.substring(i+1);
if(!set.contains(L+R)) getAns(L+R,minBracket-1,set,ans);
}
}
public int removeBracket(String s){
Stack<Character> stack=new Stack<>();
for(int i=0;i<s.length();i++){
char x=s.charAt(i);
if(x=='(') stack.push(x);
else if(x==')'){
if(!stack.isEmpty() && stack.peek()=='(') stack.pop();
else stack.push(x);
}
}
return stack.size();
}
}
Valid Palindrome
A phrase is a palindrome if, after converting all uppercase letters into lowercase letters and removing all non-alphanumeric characters, it reads the same forward and backward. Alphanumeric characters include letters and numbers.
Given a string s, return true if it is a palindrome, or false otherwise.
Example 1:
Input: s = "A man, a plan, a canal: Panama"
Output: true
Explanation: "amanaplanacanalpanama" is a palindrome.
Example 2:
Input: s = "race a car"
Output: false
Explanation: "raceacar" is not a palindrome.
Example 3:
Input: s = " "
Output: true
Explanation: s is an empty string "" after removing non-alphanumeric characters.
Since an empty string reads the same forward and backward, it is a palindrome.
Constraints:
1 <= s.length <= 2 * 105
s consists only of printable ASCII characters.
Solution 1 : Compare with Reverse
Intuition
A palindrome is a word, phrase, or sequence that reads the same backwards as forwards. e.g. madam
A palindrome, and its reverse, are identical to each other.
Algorithm
We’ll reverse the given string and compare it with the original. If those are equivalent, it’s a palindrome.
Since only alphanumeric characters are considered, we’ll filter out all other types of characters before we apply our algorithm.
Additionally, because we’re treating letters as case-insensitive, we’ll convert the remaining letters to lower case. The digits will be left the same.
Implementation
class Solution {
public boolean isPalindrome(String s) {
StringBuilder builder = new StringBuilder();
for (char ch : s.toCharArray()) {
if (Character.isLetterOrDigit(ch)) {
builder.append(Character.toLowerCase(ch));
}
}
String filteredString = builder.toString();
String reversedString = builder.reverse().toString();
return filteredString.equals(reversedString);
}
/** An alternate solution using Java 8 Streams */
public boolean isPalindromeUsingStreams(String s) {
StringBuilder builder = new StringBuilder();
s.chars()
.filter(c -> Character.isLetterOrDigit(c))
.mapToObj(c -> Character.toLowerCase((char) c))
.forEach(builder::append);
return builder.toString().equals(builder.reverse().toString());
}
}
Complexity Analysis
Time complexity : O(n), in length nn of the string.
We need to iterate thrice through the string:
-
When we filter out non-alphanumeric characters, and convert the remaining characters to lower-case.
-
When we reverse the string.
-
When we compare the original and the reversed strings.
Each iteration runs linear in time (since each character operation completes in constant time). Thus, the effective run-time complexity is linear.
Space complexity : O(n), in length nn of the string. We need O(n) additional space to stored the filtered string and the reversed string.
Solution 2 : Two Pointers
Algorithm
Since the input string contains characters that we need to ignore in our palindromic check, it becomes tedious to figure out the real middle point of our palindromic input.
Instead of going outwards from the middle, we could just go inwards towards the middle!
So, if we start traversing inwards, from both ends of the input string, we can expect to see the same characters, in the same order.
The resulting algorithm is simple:
-
Set two pointers, one at each end of the input string
-
If the input is palindromic, both the pointers should point to equivalent characters, at all times. [1]
- If this condition is not met at any point of time, we break and return early. [2]
-
We can simply ignore non-alphanumeric characters by continuing to traverse further.
-
Continue traversing inwards until the pointers meet in the middle.
Implementation
class Solution {
public boolean isPalindrome(String s) {
for (int i = 0, j = s.length() - 1; i < j; i++, j--) {
while (i < j && !Character.isLetterOrDigit(s.charAt(i))) {
i++;
}
while (i < j && !Character.isLetterOrDigit(s.charAt(j))) {
j--;
}
if (Character.toLowerCase(s.charAt(i)) != Character.toLowerCase(s.charAt(j)))
return false;
}
return true;
}
}
Complexity Analysis
Time complexity : O(n), in length n of the string. We traverse over each character at-most once, until the two pointers meet in the middle, or when we break and return early.
Space complexity : O(1). No extra space required, at all.
Solution 3 : simple java solution using stack
Implementation
public class Solution {
public boolean isValid(String s) {
Stack<Character> stack = new Stack<>();
for(int i = 0; i < s.length(); i++) {
char a = s.charAt(i);
if(a == '(' || a == '[' || a == '{') stack.push(a);
else if(stack.empty()) return false;
else if(a == ')' && stack.pop() != '(') return false;
else if(a == ']' && stack.pop() != '[') return false;
else if(a == '}' && stack.pop() != '{') return false;
}
return stack.empty();
}
}
Solution 4 :
Implementation
public class Solution {
public boolean isPalindrome(String s) {
if (s.isEmpty()) {
return true;
}
int head = 0, tail = s.length() - 1;
char cHead, cTail;
while(head <= tail) {
cHead = s.charAt(head);
cTail = s.charAt(tail);
if (!Character.isLetterOrDigit(cHead)) {
head++;
} else if(!Character.isLetterOrDigit(cTail)) {
tail--;
} else {
if (Character.toLowerCase(cHead) != Character.toLowerCase(cTail)) {
return false;
}
head++;
tail--;
}
}
return true;
}
}
First Unique Character in a String
Example 1:
Input: s = "leetcode"
Output: 0
Example 2:
Input: s = "loveleetcode"
Output: 2
Example 3:
Input: s = "aabb"
Output: -1
Constraints:
1 <= s.length <= 105
s consists of only lowercase English letters.
Solution 1 : Linear time solution
The best possible solution here could be of a linear time because to ensure that the character is unique you have to check the whole string anyway.
The idea is to go through the string and save in a hash map the number of times each character appears in the string. That would take O(N) time, where N is a number of characters in the string.
And then we go through the string the second time, this time we use the hash map as a reference to check if a character is unique or not. If the character is unique, one could just return its index. The complexity of the second iteration is O(N) as well.
Implementation
class Solution {
public int firstUniqChar(String s) {
HashMap<Character, Integer> count = new HashMap<Character, Integer>();
int n = s.length();
// build hash map : character and how often it appears
for (int i = 0; i < n; i++) {
char c = s.charAt(i);
count.put(c, count.getOrDefault(c, 0) + 1);
}
// find the index
for (int i = 0; i < n; i++) {
if (count.get(s.charAt(i)) == 1)
return i;
}
return -1;
}
}
Complexity Analysis
Time complexity : O(N) since we go through the string of length N two times.
Space complexity : O(1) because English alphabet contains 26 letters.
Maximum Number of Occurrences of a Substring
Given a string s, return the maximum number of ocurrences of any substring under the following rules:
The number of unique characters in the substring must be less than or equal to maxLetters. The substring size must be between minSize and maxSize inclusive.
Example 1:
Input: s = "aababcaab", maxLetters = 2, minSize = 3, maxSize = 4
Output: 2
Explanation: Substring "aab" has 2 ocurrences in the original string.
It satisfies the conditions, 2 unique letters and size 3 (between minSize and maxSize).
Example 2:
Input: s = "aaaa", maxLetters = 1, minSize = 3, maxSize = 3
Output: 2
Explanation: Substring "aaa" occur 2 times in the string. It can overlap.
Constraints:
1 <= s.length <= 105
1 <= maxLetters <= 26
1 <= minSize <= maxSize <= min(26, s.length)
s consists of only lowercase English letters.
Solution
The return value is the max number of the substring which follows the rule given.
It gives us a maxSize and a minSize and a maxLetters , but maxSize is useless !
If we know a substring A follows the rule occurs the max times with a size more than minSize, then this A's substring, we call it B, whose size is equal to minSize also occurs the same times and it has at most the same number of characters with A , so B also occurs the max time and follow the rule.
Implementation
class Solution {
public int maxFreq(String s, int maxLetters, int minSize, int maxSize) {
Map<String,Integer> m = new HashMap<>();
int ss = 0 ;
int ee = 0;
Map<Character,Integer> cnt = new HashMap<>();
while( ee < s.length())
{
Character cur =s.charAt(ee);
cnt.put(cur,cnt.getOrDefault(cur,0)+1);
while( ee-ss+1 > minSize )
{
Character c =s.charAt(ss);
if(cnt.get(c)==1)
cnt.remove(c);
else
cnt.put(c,cnt.get(c)-1);
ss++;
}
if(cnt.size()<=maxLetters &&ee-ss+1>=minSize )
m.put(s.substring(ss,ee+1),m.getOrDefault(s.substring(ss,ee+1),0)+1);
ee++;
}
int ans = 0 ;
for( int it : m.values())
ans= Math.max(ans,it);
return ans;
}
}
Longest Palindromic Substring
Given a string s, return the longest palindromic substring in s.
Example 1:
Input: s = "babad"
Output: "bab"
Explanation: "aba" is also a valid answer.
Example 2:
Input: s = "cbbd"
Output: "bb"
Constraints:
1 <= s.length <= 1000
s consist of only digits and English letters.
Solution 1 : Longest Common Substring
Common mistake
Some people will be tempted to come up with a quick solution, which is unfortunately flawed (however can be corrected easily):
Reverse `S` and become `S'`. Find the longest common substring between S and `S'`, which must also be the longest palindromic substring.
This seemed to work, let’s see some examples below.
For example, S = “caba”, S’ = “abac”.
The longest common substring between S and S' is “aba”, which is the answer.
Let’s try another example: S = “abacdfgdcaba”, S’ = “abacdgfdcaba”.
The longest common substring between S and S' is “abacd”. Clearly, this is not a valid palindrome.
Algorithm
We could see that the longest common substring method fails when there exists a reversed copy of a non-palindromic substring in some other part of S. To rectify this, each time we find a longest common substring candidate, we check if the substring’s indices are the same as the reversed substring’s original indices. If it is, then we attempt to update the longest palindrome found so far; if not, we skip this and find the next candidate.
This gives us an O(n^2). Dynamic Programming solution which uses O(n^2) space (could be improved to use O(n) space).
Solution 2 : Expand Around Center
In fact, we could solve it in O(n^2) time using only constant space.
We observe that a palindrome mirrors around its center. Therefore, a palindrome can be expanded from its center, and there are only 2n - 1 such centers.
You might be asking why there are 2n - 1 but not nn centers? The reason is the center of a palindrome can be in between two letters. Such palindromes have even number of letters (such as “abba”) and its center are between the two ‘b’s.
Implementation
class Solution {
public String longestPalindrome(String s) {
if (s == null || s.length() < 1) return "";
int start = 0, end = 0;
for (int i = 0; i < s.length(); i++) {
int len1 = expandAroundCenter(s, i, i);
int len2 = expandAroundCenter(s, i, i + 1);
int len = Math.max(len1, len2);
if (len > end - start) {
start = i - (len - 1) / 2;
end = i + len / 2;
}
}
return s.substring(start, end + 1);
}
private int expandAroundCenter(String s, int left, int right) {
int L = left, R = right;
while (L >= 0 && R < s.length() && s.charAt(L) == s.charAt(R)) {
L--;
R++;
}
return R - L - 1;
}
}
Complexity Analysis
Time complexity : O(n^2). Since expanding a palindrome around its center could take O(n) time, the overall complexity is O(n^2).
Space complexity : O(1).
Determine if Two Events Have Conflict
You are given two arrays of strings that represent two inclusive events that happened on the same day, event1 and event2, where:
event1 = [startTime1, endTime1]andevent2 = [startTime2, endTime2].
Event times are valid 24 hours format in the form of HH:MM.
A conflict happens when two events have some non-empty intersection (i.e., some moment is common to both events).
Return true if there is a conflict between two events. Otherwise, return false.
Example 1:
Input: event1 = ["01:15","02:00"], event2 = ["02:00","03:00"]
Output: true
Explanation: The two events intersect at time 2:00.
Example 2:
Input: event1 = ["01:00","02:00"], event2 = ["01:20","03:00"]
Output: true
Explanation: The two events intersect starting from 01:20 to 02:00.
Example 3:
Input: event1 = ["10:00","11:00"], event2 = ["14:00","15:00"]
Output: false
Explanation: The two events do not intersect.
Constraints:
evnet1.length == event2.length == 2.event1[i].length == event2[i].length == 5startTime1 <= endTime1startTime2 <= endTime2- All the event times follow the HH:MM format.
Solution
Algorithm
Given 2 segment [left1, right1], [left2, right2], how can we check whether they overlap?
If these two intervals overlap, it should exist a value x, left1 <= x <= right1 && left2 <= x <= right2 so that
max(left1, left2) <= x <= min(right1, right 2) so that
left1 <= right2 && left2 <= right1
These two are the sufficient and necessary conditions, for two interval overlaps.
Implementation
public boolean haveConflict(String[] e1, String[] e2) {
return e1[0].compareTo(e2[1]) <= 0 && e2[0].compareTo(e1[1]) <= 0;
}
Complexity Analysis
Time Complexity: O(1).
Space Complexity: O(1).
Word Search
Given an m x n grid of characters board and a string word, return true if word exists in the grid.
The word can be constructed from letters of sequentially adjacent cells, where adjacent cells are horizontally or vertically neighboring. The same letter cell may not be used more than once.
Example 1:
Input: board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
Output: true
Example 2:
Input: board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "SEE"
Output: true
Example 3:

Input: board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCB"
Output: false
Constraints:
-
m == board.length
-
n = board[i].length
-
1 <= m, n <= 6
-
1 <= word.length <= 15
-
board and word consists of only lowercase and uppercase English letters.
Solution 1 : Backtracking
Algorithm
The skeleton of the algorithm is a loop that iterates through each cell in the grid. For each cell, we invoke the backtracking function (i.e. backtrack()) to check if we would obtain a solution, starting from this very cell.
For the backtracking function backtrack(row, col, suffix), as a DFS algorithm, it is often implemented as a recursive function. The function can be broke down into the following four steps:
-
Step 1). At the beginning, first we check if we reach the bottom case of the recursion, where the word to be matched is empty, i.e. we have already found the match for each prefix of the word.
-
Step 2). We then check if the current state is invalid, either the position of the cell is out of the boundary of the board or the letter in the current cell does not match with the first letter of the word.
-
Step 3). If the current step is valid, we then start the exploration of backtracking with the strategy of DFS. First, we mark the current cell as visited, e.g. any non-alphabetic letter will do. Then we iterate through the four possible directions, namely up, right, down and left. The order of the directions can be altered, to one’s preference.
-
Step 4). At the end of the exploration, we revert the cell back to its original state. Finally we return the result of the exploration.
Implementation
class Solution {
private char[][] board;
private int ROWS;
private int COLS;
public boolean exist(char[][] board, String word) {
this.board = board;
this.ROWS = board.length;
this.COLS = board[0].length;
for (int row = 0; row < this.ROWS; ++row)
for (int col = 0; col < this.COLS; ++col)
if (this.backtrack(row, col, word, 0))
return true;
return false;
}
protected boolean backtrack(int row, int col, String word, int index) {
/* Step 1). check the bottom case. */
if (index >= word.length())
return true;
/* Step 2). Check the boundaries. */
if (row < 0 || row == this.ROWS || col < 0 || col == this.COLS
|| this.board[row][col] != word.charAt(index))
return false;
/* Step 3). explore the neighbors in DFS */
boolean ret = false;
// mark the path before the next exploration
this.board[row][col] = '#';
int[] rowOffsets = {0, 1, 0, -1};
int[] colOffsets = {1, 0, -1, 0};
for (int d = 0; d < 4; ++d) {
ret = this.backtrack(row + rowOffsets[d], col + colOffsets[d], word, index + 1);
if (ret)
break;
}
/* Step 4). clean up and return the result. */
this.board[row][col] = word.charAt(index);
return ret;
}
}
Notes
There are a few choices that we made for our backtracking algorithm, here we elaborate some thoughts that are behind those choices.
Instead of returning directly once we find a match, we simply break out of the loop and do the cleanup before returning.
Here is what the alternative solution might look like.
public class solution {
protected boolean backtrack(int row, int col, String word, int index) {
/* Step 1). check the bottom case. */
if (index >= word.length())
return true;
/* Step 2). Check the boundaries. */
if (row < 0 || row == this.ROWS || col < 0 || col == this.COLS
|| this.board[row][col] != word.charAt(index))
return false;
/* Step 3). explore the neighbors in DFS */
// mark the path before the next exploration
this.board[row][col] = '#';
int[] rowOffsets = {0, 1, 0, -1};
int[] colOffsets = {1, 0, -1, 0};
for (int d = 0; d < 4; ++d) {
if (this.backtrack(row + rowOffsets[d], col + colOffsets[d], word, index + 1))
// return without cleanup
return true;
}
/* Step 4). clean up and return the result. */
this.board[row][col] = word.charAt(index);
return false;
}
}
As one may notice, we simply return True if the result of the recursive call to backtrack() is positive. Though this minor modification would have no impact on the time or space complexity, it would however leave with a “side-effect,” i.e. the matched letters in the original board would be altered to #.
Instead of doing the boundary checks before the recursive call on the backtrack() function, we do it within the function.
This is an important choice though. Doing the boundary check within the function would allow us to reach the bottom case, for the test case where the board contains only a single cell, since either of neighbor indices would not be valid.
Complexity Analysis
Time Complexity: O(N.3^L) where N is the number of cells in the board and L is the length of the word to be matched.
-
For the backtracking function, initially we could have at most 4 directions to explore, but further the choices are reduced into 3 (since we won’t go back to where we come from). As a result, the execution trace after the first step could be visualized as a 3-ary tree, each of the branches represent a potential exploration in the corresponding direction. Therefore, in the worst case, the total number of invocation would be the number of nodes in a full 3-nary tree, which is about 3^L.
-
We iterate through the board for backtracking, i.e. there could be N times invocation for the backtracking function in the worst case.
-
As a result, overall the time complexity of the algorithm would be O(N.3^L).
Space Complexity: O(L) where L is the length of the word to be matched.
- The main consumption of the memory lies in the recursion call of the backtracking function. The maximum length of the call stack would be the length of the word. Therefore, the space complexity of the algorithm is O(L).
Permutation in String
Given two strings s1 and s2, return true if s2 contains a permutation of s1, or false otherwise.
In other words, return true if one of s1's permutations is the substring of s2.
Example 1:
Input: s1 = "ab", s2 = "eidbaooo"
Output: true
Explanation: s2 contains one permutation of s1 ("ba").
Example 2:
Input: s1 = "ab", s2 = "eidboaoo"
Output: false
Constraints:
-
1 <= s1.length, s2.length <= 104 -
s1ands2consist of lowercase English letters.
Solution 1 : Brute Force
Algorithm
The simplest method is to generate all the permutations of the short string and to check if the generated permutation is a substring of the longer string.
In order to generate all the possible pairings, we make use of a function permute(string_1, string_2, current_index). This function creates all the possible permutations of the short string s1s1.
To do so, permute takes the index of the current element current_index as one of the arguments. Then, it swaps the current element with every other element in the array, lying towards its right, so as to generate a new ordering of the array elements. After the swapping has been done, it makes another call to permute but this time with the index of the next element in the array. While returning back, we reverse the swapping done in the current function call.
Implementation
public class Solution {
boolean flag = false;
public boolean checkInclusion(String s1, String s2) {
permute(s1, s2, 0);
return flag;
}
public String swap(String s, int i0, int i1) {
if (i0 == i1)
return s;
String s1 = s.substring(0, i0);
String s2 = s.substring(i0 + 1, i1);
String s3 = s.substring(i1 + 1);
return s1 + s.charAt(i1) + s2 + s.charAt(i0) + s3;
}
void permute(String s1, String s2, int l) {
if (l == s1.length()) {
if (s2.indexOf(s1) >= 0)
flag = true;
} else {
for (int i = l; i < s1.length(); i++) {
s1 = swap(s1, l, i);
permute(s1, s2, l + 1);
s1 = swap(s1, l, i);
}
}
}
}
Complexity Analysis
Let n be the length of s1
Time complexity: O(n!).
Space complexity: O(n^2). The depth of the recursion tree is n(n refers to the length of the short string s1). Every node of the recursion tree contains a string of max. length n.
Solution 2 : Using sorting
Algorithm
The idea behind this approach is that one string will be a permutation of another string only if both of them contain the same characters the same number of times. One string x is a permutation of other string y only if sorted(x)=sorted(y).
In order to check this, we can sort the two strings and compare them. We sort the short string s1 and all the substrings of s2, sort them and compare them with the sorted s1 string. If the two match completely, s1’s permutation is a substring of s2, otherwise not.
Implementation
public class Solution {
public boolean checkInclusion(String s1, String s2) {
s1 = sort(s1);
for (int i = 0; i <= s2.length() - s1.length(); i++) {
if (s1.equals(sort(s2.substring(i, i + s1.length()))))
return true;
}
return false;
}
public String sort(String s) {
char[] t = s.toCharArray();
Arrays.sort(t);
return new String(t);
}
}
Complexity Analysis
Let l_1 be the length of string s_1 and l_2 be the length of string s_2.
Time complexity: O(l_1log(l_1)+(l_2-l_1)l_1log(l_1).
Space complexity: O(l_1). t array is used.
Solution 3 : Using Hashmap
Algorithm
As discussed above, one string will be a permutation of another string only if both of them contain the same characters with the same frequency. We can consider every possible substring in the long string s2 of the same length as that of s1 and check the frequency of occurence of the characters appearing in the two. If the frequencies of every letter match exactly, then only s1’s permutation can be a substring of s2.
In order to implement this approach, instead of sorting and then comparing the elements for equality, we make use of a hashmap s1maps1map which stores the frequency of occurence of all the characters in the short string s1. We consider every possible substring of s2 of the same length as that of s1, find its corresponding hashmap as well, namely s2maps2map. Thus, the substrings considered can be viewed as a window of length as that of s1 iterating over s2. If the two hashmaps obtained are identical for any such window, we can conclude that s1’s permutation is a substring of s2, otherwise not.
Implementation
public class Solution {
public boolean checkInclusion(String s1, String s2) {
if (s1.length() > s2.length())
return false;
HashMap<Character, Integer> s1map = new HashMap<>();
for (int i = 0; i < s1.length(); i++)
s1map.put(s1.charAt(i), s1map.getOrDefault(s1.charAt(i), 0) + 1);
for (int i = 0; i <= s2.length() - s1.length(); i++) {
HashMap<Character, Integer> s2map = new HashMap<>();
for (int j = 0; j < s1.length(); j++) {
s2map.put(s2.charAt(i + j), s2map.getOrDefault(s2.charAt(i + j), 0) + 1);
}
if (matches(s1map, s2map))
return true;
}
return false;
}
public boolean matches(HashMap<Character, Integer> s1map, HashMap<Character, Integer> s2map) {
for (char key : s1map.keySet()) {
if (s1map.get(key) - s2map.getOrDefault(key, -1) != 0)
return false;
}
return true;
}
}
Complexity Analysis
Let l_1 be the length of string s_1 and l_2 be the length of string s_2.
Time complexity: O(l_1+26l_1(l_2-l_1)). The hashmap contains atmost 26 keys.
Space complexity: O(1). Hashmap contains at most 26 key-value pairs.
Solution 4 : Using Array [Accepted]
Algorithm
Instead of making use of a special HashMap datastructure just to store the frequency of occurence of characters, we can use a simpler array data structure to store the frequencies. Given strings contains only lowercase alphabets (‘a’ to ‘z’). So we need to take an array of size 26.The rest of the process remains the same as the last approach.
Implementation
public class Solution {
public boolean checkInclusion(String s1, String s2) {
if (s1.length() > s2.length())
return false;
int[] s1map = new int[26];
for (int i = 0; i < s1.length(); i++)
s1map[s1.charAt(i) - 'a']++;
for (int i = 0; i <= s2.length() - s1.length(); i++) {
int[] s2map = new int[26];
for (int j = 0; j < s1.length(); j++) {
s2map[s2.charAt(i + j) - 'a']++;
}
if (matches(s1map, s2map))
return true;
}
return false;
}
public boolean matches(int[] s1map, int[] s2map) {
for (int i = 0; i < 26; i++) {
if (s1map[i] != s2map[i])
return false;
}
return true;
}
}
Complexity Analysis
Let l_1 be the length of string s_1 and l_2 be the length of string s_2.
Time complexity: O(l_1+26l_1(l_2-l_1)). The hashmap contains atmost 26 keys.
Space complexity: O(1). s1map and s2map of size 26 is used.
Balanced Binary Tree
Given a binary tree, determine if it is height-balanced.
Example 1 :
Input: root = [3,9,20,null,null,15,7]
Output: true
Example 2:
Input: root = [1,2,2,3,3,null,null,4,4]
Output: false
Example 3:
Input: root = []
Output: true
Constraints:
-
The number of nodes in the tree is in the range
[0, 5000]. -
-104 <= Node.val <= 104
Solution 1 : Top-down recursion
Algorithm
First we define a function height such that for any node p ∈ T
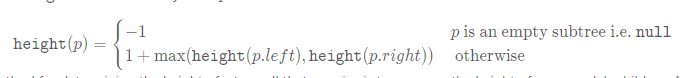
Now that we have a method for determining the height of a tree, all that remains is to compare the height of every node’s children. A tree T rooted at r is balanced if and only if the height of its two children are within 1 of each other and the subtrees at each child are also balanced. Therefore, we can compare the two child subtrees’ heights then recurse on each one.
isBalanced(root):
if (root == NULL):
return true
if (abs(height(root.left) - height(root.right)) > 1):
return false
else:
return isBalanced(root.left) && isBalanced(root.right)
class Solution {
// Recursively obtain the height of a tree. An empty tree has -1 height
private int height(TreeNode root) {
// An empty tree has height -1
if (root == null) {
return -1;
}
return 1 + Math.max(height(root.left), height(root.right));
}
public boolean isBalanced(TreeNode root) {
// An empty tree satisfies the definition of a balanced tree
if (root == null) {
return true;
}
// Check if subtrees have height within 1. If they do, check if the
// subtrees are balanced
return Math.abs(height(root.left) - height(root.right)) < 2
&& isBalanced(root.left)
&& isBalanced(root.right);
}
}
Complexity Analysis
Time complexity :

Space complexity : O(n). The recursion stack may contain all nodes if the tree is skewed.
Fun fact: f(n) = f(n-1) + f(n-2) + 1 is known as a Fibonacci meanders sequence.
Solution 2 : Bottom-up recursion
Intuition
In approach 1, we perform redundant calculations when computing height. In each call to height, we require that the subtree’s heights also be computed. Therefore, when working top down we will compute the height of a subtree once for every parent. We can remove the redundancy by first recursing on the children of the current node and then using their computed height to determine whether the current node is balanced.
Algorithm
We will use the same height defined in the first approach. The bottom-up approach is a reverse of the logic of the top-down approach since we first check if the child subtrees are balanced before comparing their heights. The algorithm is as follows:
Check if the child subtrees are balanced. If they are, use their heights to determine if the current subtree is balanced as well as to calculate the current subtree's height.
Implementation
// Utility class to store information from recursive calls
final class TreeInfo {
public final int height;
public final boolean balanced;
public TreeInfo(int height, boolean balanced) {
this.height = height;
this.balanced = balanced;
}
}
class Solution {
// Return whether or not the tree at root is balanced while also storing
// the tree's height in a reference variable.
private TreeInfo isBalancedTreeHelper(TreeNode root) {
// An empty tree is balanced and has height = -1
if (root == null) {
return new TreeInfo(-1, true);
}
// Check subtrees to see if they are balanced.
TreeInfo left = isBalancedTreeHelper(root.left);
if (!left.balanced) {
return new TreeInfo(-1, false);
}
TreeInfo right = isBalancedTreeHelper(root.right);
if (!right.balanced) {
return new TreeInfo(-1, false);
}
// Use the height obtained from the recursive calls to
// determine if the current node is also balanced.
if (Math.abs(left.height - right.height) < 2) {
return new TreeInfo(Math.max(left.height, right.height) + 1, true);
}
return new TreeInfo(-1, false);
}
public boolean isBalanced(TreeNode root) {
return isBalancedTreeHelper(root).balanced;
}
}
Complexity Analysis
Time complexity : O(n)
For every subtree, we compute its height in constant time as well as compare the height of its children.
Space complexity : O(n). The recursion stack may go up to O(n) if the tree is unbalanced.
Zigzag Conversion
The string “PAYPALISHIRING” is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)
P A H N
A P L S I I G
Y I R
And then read line by line: “PAHNAPLSIIGYIR”
Write the code that will take a string and make this conversion given a number of rows:
string convert(string s, int numRows);
Example 1:
Input: s = "PAYPALISHIRING", numRows = 3
Output: "PAHNAPLSIIGYIR"
Example 2:
Input: s = "PAYPALISHIRING", numRows = 4
Output: "PINALSIGYAHRPI"
Explanation:
P I N
A L S I G
Y A H R
P I
Example 3:
Input: s = "A", numRows = 1
Output: "A"
Constraints:
-
1 <= s.length <= 1000 -
sconsists of English letters (lower-case and upper-case),,and.. -
1 <= numRows <= 1000
Solution 1 : Sort by Row
Intuition
By iterating through the string from left to right, we can easily determine which row in the Zig-Zag pattern that a character belongs to.
Algorithm
We can use min(numRows,len(s)) lists to represent the non-empty rows of the Zig-Zag Pattern.
Iterate through s from left to right, appending each character to the appropriate row. The appropriate row can be tracked using two variables: the current row and the current direction.
The current direction changes only when we moved up to the topmost row or moved down to the bottommost row.
Implementation
class Solution {
public String convert(String s, int numRows) {
if (numRows == 1) return s;
List<StringBuilder> rows = new ArrayList<>();
for (int i = 0; i < Math.min(numRows, s.length()); i++)
rows.add(new StringBuilder());
int curRow = 0;
boolean goingDown = false;
for (char c : s.toCharArray()) {
rows.get(curRow).append(c);
if (curRow == 0 || curRow == numRows - 1) goingDown = !goingDown;
curRow += goingDown ? 1 : -1;
}
StringBuilder ret = new StringBuilder();
for (StringBuilder row : rows) ret.append(row);
return ret.toString();
}
}
Complexity Analysis
Time Complexity: O(n), where n ==len(s).
Space Complexity: O(n)
Solution 2 : Visit by Row
Intuition
Visit the characters in the same order as reading the Zig-Zag pattern line by line.
Algorithm
Visit all characters in row 0 first, then row 1, then row 2, and so on…
For all whole numbers k,
-
Characters in row 0 are located at indexes k(2⋅numRows−2)
-
Characters in row numRows−1 are located at indexes k(2⋅numRows−2)+numRows−1
-
Characters in inner row i are located at indexes k(2⋅numRows−2) + i and (k+1)(2⋅numRows−2) − i.
Implementation
class Solution {
public String convert(String s, int numRows) {
if (numRows == 1) return s;
StringBuilder ret = new StringBuilder();
int n = s.length();
int cycleLen = 2 * numRows - 2;
for (int i = 0; i < numRows; i++) {
for (int j = 0; j + i < n; j += cycleLen) {
ret.append(s.charAt(j + i));
if (i != 0 && i != numRows - 1 && j + cycleLen - i < n)
ret.append(s.charAt(j + cycleLen - i));
}
}
return ret.toString();
}
}
Complexity Analysis
Time Complexity: O(n), where n==len(s). Each index is visited once.
Space Complexity: O(n). For the cpp implementation, O(1) if return string is not considered extra space.
Validate Binary Search Tree
Given the root of a binary tree, determine if it is a valid binary search tree (BST).
A valid BST is defined as follows:
-
The left subtree of a node contains only nodes with keys
less thanthe node’s key. -
The right subtree of a node contains only nodes with keys
greater thanthe node’s key. -
Both the left and right subtrees must also be binary search trees.
Example : 1
Input: root = [2,1,3]
Output: true
Example: 2
 `
`
Input: root = [5,1,4,null,null,3,6]
Output: false
Explanation: The root node's value is 5 but its right child's value is 4.
Constraints:
-
The number of nodes in the tree is in the range
[1, 104]. -
-231 <= Node.val <= 231 - 1
Solution 1 : Recursive Traversal with Valid Range
Tree definition
First of all, here is the definition of the TreeNode which we would use.
// Definition for a binary tree node.
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) {
val = x;
}
}
Implementation
class Solution {
public boolean validate(TreeNode root, Integer low, Integer high) {
// Empty trees are valid BSTs.
if (root == null) {
return true;
}
// The current node's value must be between low and high.
if ((low != null && root.val <= low) || (high != null && root.val >= high)) {
return false;
}
// The left and right subtree must also be valid.
return validate(root.right, root.val, high) && validate(root.left, low, root.val);
}
public boolean isValidBST(TreeNode root) {
return validate(root, null, null);
}
}
Complexity Analysis
Time complexity : O(N) since we visit each node exactly once.
Space complexity : O(N) since we keep up to the entire tree.
Solution 2 : Iterative Traversal with Valid Range
The above recursion could be converted into iteration, with the help of an explicit stack. DFS would be better than BFS since it works faster here.
class Solution {
private Deque<TreeNode> stack = new LinkedList();
private Deque<Integer> upperLimits = new LinkedList();
private Deque<Integer> lowerLimits = new LinkedList();
public void update(TreeNode root, Integer low, Integer high) {
stack.add(root);
lowerLimits.add(low);
upperLimits.add(high);
}
public boolean isValidBST(TreeNode root) {
Integer low = null, high = null, val;
update(root, low, high);
while (!stack.isEmpty()) {
root = stack.poll();
low = lowerLimits.poll();
high = upperLimits.poll();
if (root == null) continue;
val = root.val;
if (low != null && val <= low) {
return false;
}
if (high != null && val >= high) {
return false;
}
update(root.right, val, high);
update(root.left, low, val);
}
return true;
}
}
Complexity Analysis
Time complexity : O(N) since we visit each node exactly once.
Space complexity : O(N) since we keep up to the entire tree.
Solution 3 : Recursive Inorder Traversal
class Solution {
// We use Integer instead of int as it supports a null value.
private Integer prev;
public boolean isValidBST(TreeNode root) {
prev = null;
return inorder(root);
}
private boolean inorder(TreeNode root) {
if (root == null) {
return true;
}
if (!inorder(root.left)) {
return false;
}
if (prev != null && root.val <= prev) {
return false;
}
prev = root.val;
return inorder(root.right);
}
}
Complexity Analysis
Time complexity : O(N) in the worst case when the tree is a BST or the “bad” element is a rightmost leaf.
Space complexity : O(N) for the space on the run-time stack.
Solution 4 : Iterative Inorder Traversal
Alternatively, we could implement the above algorithm iteratively.
class Solution {
public boolean isValidBST(TreeNode root) {
Deque<TreeNode> stack = new ArrayDeque<>();
Integer prev = null;
while (!stack.isEmpty() || root != null) {
while (root != null) {
stack.push(root);
root = root.left;
}
root = stack.pop();
// If next element in inorder traversal
// is smaller than the previous one
// that's not BST.
if (prev != null && root.val <= prev) {
return false;
}
prev = root.val;
root = root.right;
}
return true;
}
}
Complexity Analysis
Time complexity : O(N) in the worst case when the tree is BST or the “bad” element is a rightmost leaf.
Space complexity : O(N) to keep stack.
Remove Duplicates from Sorted Array II
Given an integer array nums sorted in non-decreasing order, remove some duplicates in-place such that each unique element appears at most twice. The relative order of the elements should be kept the same.
Since it is impossible to change the length of the array in some languages, you must instead have the result be placed in the first part of the array nums. More formally, if there are k elements after removing the duplicates, then the first k elements of nums should hold the final result. It does not matter what you leave beyond the first k elements.
Return k after placing the final result in the first k slots of nums.
Do not allocate extra space for another array. You must do this by modifying the input array in-place with O(1) extra memory.
Custom Judge:
The judge will test your solution with the following code:
int[] nums = [...]; // Input array
int[] expectedNums = [...]; // The expected answer with correct length
int k = removeDuplicates(nums); // Calls your implementation
assert k == expectedNums.length;
for (int i = 0; i < k; i++) {
assert nums[i] == expectedNums[i];
}
If all assertions pass, then your solution will be accepted.
Example 1:
Input: nums = [1,1,1,2,2,3]
Output: 5, nums = [1,1,2,2,3,_]
Explanation: Your function should return k = 5, with the first five elements of nums being 1, 1, 2, 2 and 3 respectively.
It does not matter what you leave beyond the returned k (hence they are underscores).
Example 2:
Input: nums = [0,0,1,1,1,1,2,3,3]
Output: 7, nums = [0,0,1,1,2,3,3,_,_]
Explanation: Your function should return k = 7, with the first seven elements of nums being 0, 0, 1, 1, 2, 3 and 3 respectively.
It does not matter what you leave beyond the returned k (hence they are underscores).
Constraints:
-
1 <= nums.length <= 3 * 104 -
-104 <= nums[i] <= 104 -
numsis sorted in non-decreasing order.
Solution 1 : Popping Unwanted Duplicates
Intuition
The input array is already sorted and hence, all the duplicates appear next to each other. The problem statement mentions that we are not allowed to use any additional space and we have to modify the array in-place. The easiest approach for in-place modifications would be to get rid of all the unwanted duplicates. For every number in the array, if we detect > 2 duplicates, we simply remove them from the list of elements and we do this for all the elements in the array.
Algorithm
-
The implementation is slightly tricky so to say since we will be removing elements from the array and iterating over it at the same time. So, we need to keep updating the array’s indexes as and when we pop an element else we’ll be accessing invalid indexes.
-
Say we have two variables, i which is the array pointer and count which keeps track of the count of a particular element in the array. Note that the minimum count would always be 1.
-
We start with index 1 and process one element at a time in the array.
-
If we find that the current element is the same as the previous element i.e. nums[i] == nums[i - 1], then we increment the count. If the value of count > 2, then we have encountered an unwanted duplicate element and we can remove it from the array. Since we know the index of this element, we can use the del or pop or remove operation (or whatever corresponding operation is supported in your language of choice) to delete the element at index i from the array. Since we popped an element, we decrement the index by 1 as well.
-
If we encounter that the current element is not the same as the previous element i.e. nums[i] != nums[i - 1], then it means we have a new element at hand and so accordingly, we update count = 1.
-
Since we are removing all the unwanted duplicates from the original array, the final array that remains after process all the elements will only contain the valid elements and hence we simply return the length of this array.
Implementation
class Solution {
public int[] remElement(int[] arr, int index) {
//
// Overwrite the element at the given index by
// moving all the elements to the right of the
// index, one position to the left.
//
for (int i = index + 1; i < arr.length; i++) {
arr[i - 1] = arr[i];
}
return arr;
}
public int removeDuplicates(int[] nums) {
// Initialize the counter and the array index.
int i = 1, count = 1, length = nums.length;
//
// Start from the second element of the array and process
// elements one by one.
//
while (i < length) {
//
// If the current element is a duplicate,
// increment the count.
//
if (nums[i] == nums[i - 1]) {
count++;
//
// If the count is more than 2, this is an unwanted duplicate element
// and hence we remove it from the array.
//
if (count > 2) {
this.remElement(nums, i);
//
// Note that we have to decrement the array index value to
// keep it consistent with the size of the array.
//
i--;
//
// Since we have a fixed size array and we can't actually
// remove an element, we reduce the length of the array as
// well.
//
length--;
}
} else {
//
// Reset the count since we encountered a different element
// than the previous one.
//
count = 1;
}
// Move on to the next element in the array
i++;
}
return length;
}
}
Complexity Analysis
Time Complexity: Let’s see what the costly operations in our array are:
-
We have to iterate over all the elements in the array. Suppose that the original array contains N elements, the time taken here would be O(N).
-
Next, for every unwanted duplicate element, we will have to perform a delete operation and deletions in arrays are also O(N).
-
The worst case would be when all the elements in the array are the same. In that case, we would be performing N−2 deletions thus giving us O(N^2) complexity for deletions
-
Overall complexity = O(N) + O(N^2) ≡ O(N^2).
Space Complexity: O(1) since we are modifying the array in-place.
Solution 2 : Overwriting unwanted duplicates
Intuition
The second approach is really inspired by the fact that the problem statement asks us to return the new length of the array from the function. If all we had to do was remove elements, the function would not really ask us to return the updated length. However, in our scenario, this is really an indication that we don’t need to actually remove elements from the array. Instead, we can do something better and simply overwrite the duplicate elements that are unwanted.
We won't be able to achieve this using a single pointer. We will be using a two-pointer approach where one pointer iterates over the original set of elements and another one that keeps track of the next "empty" location in the array or the next location that can be overwritten in the array.
Implementation
class Solution {
public int removeDuplicates(int[] nums) {
//
// Initialize the counter and the second pointer.
//
int j = 1, count = 1;
//
// Start from the second element of the array and process
// elements one by one.
//
for (int i = 1; i < nums.length; i++) {
//
// If the current element is a duplicate, increment the count.
//
if (nums[i] == nums[i - 1]) {
count++;
} else {
//
// Reset the count since we encountered a different element
// than the previous one.
//
count = 1;
}
//
// For a count <= 2, we copy the element over thus
// overwriting the element at index "j" in the array
//
if (count <= 2) {
nums[j++] = nums[i];
}
}
return j;
}
}
Complexity Analysis
Time Complexity: O(N) since we process each element exactly once.
Space Complexity: O(1).
Backspace String Compare
Given two strings s and t, return true if they are equal when both are typed into empty text editors. # means a backspace character.
Note that after backspacing an empty text, the text will continue empty.
Example 1:
Input: s = "ab#c", t = "ad#c"
Output: true
Explanation: Both s and t become "ac".
Example 2:
Input: s = "ab##", t = "c#d#"
Output: true
Explanation: Both s and t become "".
Example 3:
Input: s = "a#c", t = "b"
Output: false
Explanation: s becomes "c" while t becomes "b".
Constraints:
-
1 <= s.length, t.length <= 200 -
sandtonly contain lowercase letters and ‘#’ characters.
Solution 1 : Build String [Accepted]
Intuition
Let’s individually build the result of each string (build(S) and build(T)), then compare if they are equal.
Algorithm
To build the result of a string build(S), we’ll use a stack based approach, simulating the result of each keystroke.
Implementation
class Solution {
public boolean backspaceCompare(String S, String T) {
return build(S).equals(build(T));
}
public String build(String S) {
Stack<Character> ans = new Stack();
for (char c: S.toCharArray()) {
if (c != '#')
ans.push(c);
else if (!ans.empty())
ans.pop();
}
return String.valueOf(ans);
}
}
Complexity Analysis
Time Complexity: O(M+N), where M,N are the lengths of S and T respectively.
Space Complexity: O(M+N).
Solution 2 : Two Pointer [Accepted]
Intuition
When writing a character, it may or may not be part of the final string depending on how many backspace keystrokes occur in the future.
If instead we iterate through the string in reverse, then we will know how many backspace characters we have seen, and therefore whether the result includes our character.
Algorithm
Iterate through the string in reverse. If we see a backspace character, the next non-backspace character is skipped. If a character isn’t skipped, it is part of the final answer.
See the comments in the code for more details.
Implementation
class Solution {
public boolean backspaceCompare(String S, String T) {
int i = S.length() - 1, j = T.length() - 1;
int skipS = 0, skipT = 0;
while (i >= 0 || j >= 0) { // While there may be chars in build(S) or build (T)
while (i >= 0) { // Find position of next possible char in build(S)
if (S.charAt(i) == '#') {skipS++; i--;}
else if (skipS > 0) {skipS--; i--;}
else break;
}
while (j >= 0) { // Find position of next possible char in build(T)
if (T.charAt(j) == '#') {skipT++; j--;}
else if (skipT > 0) {skipT--; j--;}
else break;
}
// If two actual characters are different
if (i >= 0 && j >= 0 && S.charAt(i) != T.charAt(j))
return false;
// If expecting to compare char vs nothing
if ((i >= 0) != (j >= 0))
return false;
i--; j--;
}
return true;
}
}
Complexity Analysis
Time Complexity: O(M+N), where M,N are the lengths of S and T respectively.
Space Complexity: O(1).
Solution 3 : StringBuilder
Implementation
public class Solution {
public boolean backspaceCompare(String S, String T) {
return sb(S).equals(sb(T));
}
private String sb(String str) {
StringBuilder sbr = new StringBuilder();
for (char c : str.toCharArray()) {
if (c != '#') {
sbr.append(c);
} else if (sbr.length() != 0) {
sbr.deleteCharAt(sbr.length() - 1);
}
}
return sbr.toString();
}
}
Solution 4 : Stack
Implementation
public class Solution {
public boolean backspaceCompare(String S, String T) {
return stackSolution(S).equals(stackSolution(T));
}
private String stackSolution(String str) {
Stack<Character> stack = new Stack<Character>();
for (char c : str.toCharArray()) {
if (c != '#') {
stack.push(c);
} else if (!stack.isEmpty()) {
stack.pop();
}
}
return stack.toString();
}
}
Palindromic Substrings
Given a string s, return the number of **palindromic substrings in it.
A string is a palindrome when it reads the same backward as forward.
A substring is a contiguous sequence of characters within the string.
Example 1:
Input: s = "abc"
Output: 3
Explanation: Three palindromic strings: "a", "b", "c".
Example 2:
Input: s = "aaa"
Output: 6
Explanation: Six palindromic strings: "a", "a", "a", "aa", "aa", "aaa".
Constraints:
-
1 <= s.length <= 1000 -
sconsists of lowercase English letters.
Solution 1 : Check All Substrings
Intuition
Just do what the question says! We look at all substrings of the input string and check if they are palindromes.
Algorithm
Each substring is denoted by a pair of variables pointing to the start and end indices of the sub-string.
A single character substring is denoted by start and end indices being equal in value.
Checking for a palindrome is simple; we check if the ends of the substring are the same character, going outside-in:
-
If they aren’t, this substring is not a palindrome.
-
Else, we continue checking inwards until we get to the middle.
Implementation
class Solution {
private boolean isPalindrome(String s, int start, int end) {
while (start < end) {
if (s.charAt(start) != s.charAt(end))
return false;
++start;
--end;
}
return true;
}
public int countSubstrings(String s) {
int ans = 0;
for (int start = 0; start < s.length(); ++start)
for (int end = start; end < s.length(); ++end)
ans += isPalindrome(s, start, end) ? 1 : 0;
return ans;
}
}
Complexity Analysis
Time Complexity: O(N^3) for input string of length N.
Space Complexity: O(1). We don’t need to allocate any extra space since we are repeatedly iterating on the input string itself.
Solution 2 : Dynamic Programming
Implementation
class Solution {
public int countSubstrings(String s) {
int n = s.length(), ans = 0;
if (n <= 0)
return 0;
boolean[][] dp = new boolean[n][n];
// Base case: single letter substrings
for (int i = 0; i < n; ++i, ++ans)
dp[i][i] = true;
// Base case: double letter substrings
for (int i = 0; i < n - 1; ++i) {
dp[i][i + 1] = (s.charAt(i) == s.charAt(i + 1));
ans += (dp[i][i + 1] ? 1 : 0);
}
// All other cases: substrings of length 3 to n
for (int len = 3; len <= n; ++len)
for (int i = 0, j = i + len - 1; j < n; ++i, ++j) {
dp[i][j] = dp[i + 1][j - 1] && (s.charAt(i) == s.charAt(j));
ans += (dp[i][j] ? 1 : 0);
}
return ans;
}
}
Complexity Analysis
Time Complexity: O(N^2) for input string of length N.
Space Complexity: O(N^2)for an input string of length N.
Solution 3 : Expand Around Possible Centers
Implementation
class Solution {
public int countSubstrings(String s) {
int ans = 0;
for (int i = 0; i < s.length(); ++i) {
// odd-length palindromes, single character center
ans += countPalindromesAroundCenter(s, i, i);
// even-length palindromes, consecutive characters center
ans += countPalindromesAroundCenter(s, i, i + 1);
}
return ans;
}
private int countPalindromesAroundCenter(String ss, int lo, int hi) {
int ans = 0;
while (lo >= 0 && hi < ss.length()) {
if (ss.charAt(lo) != ss.charAt(hi))
break; // the first and last characters don't match!
// expand around the center
lo--;
hi++;
ans++;
}
return ans;
}
}
Complexity Analysis
Time Complexity: O(N^2) for input string of length N.
Space Complexity: O(1).
Valid Palindrome II
Given a string s, return true if the s can be palindrome after deleting at most one character from it.
Example 1:
Input: s = "aba"
Output: true
Example 2:
Input: s = "abca"
Output: true
Explanation: You could delete the character 'c'.
Example 3:
Input: s = "abc"
Output: false
Constraints:
-
1 <= s.length <= 105 -
sconsists of lowercase English letters.
Solution 1 : Two Pointers
Implementation
class Solution {
private boolean checkPalindrome(String s, int i, int j) {
while (i < j) {
if (s.charAt(i) != s.charAt(j)) {
return false;
}
i++;
j--;
}
return true;
}
public boolean validPalindrome(String s) {
int i = 0;
int j = s.length() - 1;
while (i < j) {
// Found a mismatched pair - try both deletions
if (s.charAt(i) != s.charAt(j)) {
return (checkPalindrome(s, i, j - 1) || checkPalindrome(s, i + 1, j));
}
i++;
j--;
}
return true;
}
}
Complexity Analysis
Given N as the length of s,
Time complexity: O(N).
Space complexity: O(1).
Reverse String
Write a function that reverses a string. The input string is given as an array of characters s.
You must do this by modifying the input array in-place with O(1) extra memory.
Example 1:
Input: s = ["h","e","l","l","o"]
Output: ["o","l","l","e","h"]
Example 2:
Input: s = ["H","a","n","n","a","h"]
Output: ["h","a","n","n","a","H"]
Constraints:
-
1 <= s.length <= 105 -
s[i]is a printable ascii character.
Solution 1 : Recursion, In-Place, O(N) Space
Algorithm
Here is an example. Let’s implement recursive function helper which receives two pointers, left and right, as arguments.
Base case: if left >= right, do nothing.
Otherwise, swap s[left] and s[right] and call helper(left + 1, right - 1).
To solve the problem, call helper function passing the head and tail indexes as arguments: return helper(0, len(s) - 1).
Implementation
class Solution {
public void helper(char[] s, int left, int right) {
if (left >= right) return;
char tmp = s[left];
s[left++] = s[right];
s[right--] = tmp;
helper(s, left, right);
}
public void reverseString(char[] s) {
helper(s, 0, s.length - 1);
}
}
Complexity Analysis
Time complexity : O(N) time to perform N/2 swaps.
Space complexity : O(N) to keep the recursion stack.
Solution 2 : Two Pointers, Iteration, O(1) Space
Implementation
class Solution {
public void reverseString(char[] s) {
int left = 0, right = s.length - 1;
while (left < right) {
char tmp = s[left];
s[left++] = s[right];
s[right--] = tmp;
}
}
}
Complexity Analysis
Time complexity : O(N) to swap N/2 element.
Space complexity : O(1), it’s a constant space solution.
Solution 3 : Simple Multiple solutions w/explanations!
Implementation 1 : 1ms
public void reverseString(char[] s) {
for(int i=0; i<s.length/2; i++){ //Do it half the number of String length
char tmp = s[i];
s[i] = s[s.length-1-i]; //Front swap with other End side
s[s.length-1-i] = tmp; //End swap with other Front side
}
}
Implementation 2 : 400ms
public class Solution {
public void reverseString(char[] s) {
String str = ""; //Allocate extra space
for(int i=s.length-1; i>=0; i--) /*Add to extra space from rear to front */
str += s[i];
for(int i=0; i<s.length; i++) /*Set reversed 'str' into char array 's' */
s[i] = str.charAt(i);
}
}
String To Integer
Problem Statement
Implement atoi which converts a string to an integer.
The function first discards as many whitespace characters as necessary until the first non-whitespace character is found. Then, starting from this character takes an optional initial plus or minus sign followed by as many numerical digits as possible, and interprets them as a numerical value.
The string can contain additional characters after those that form the integral number, which are ignored and have no effect on the behavior of this function.
If the first sequence of non-whitespace characters in str is not a valid integral number, or if no such sequence exists because either str is empty or it contains only whitespace characters, no conversion is performed.
If no valid conversion could be performed, a zero value is returned.
Note:
Only the space character ’ ’ is considered a whitespace character. Assume we are dealing with an environment that could only store integers within the 32-bit signed integer range: [−231, 231 − 1]. If the numerical value is out of the range of representable values, INTMAX (231 − 1) or INTMIN (−231) is returned.
Constraints
-
0 <= s.length <= 200 -
sconsists of English letters (lower-case and upper-case), digits,’ ’,’+’,’-’and’.‘.
Example 1:
Input: str = "42"
Output: 42
Example 2:
Input: str = " -42"
Output: -42
Explanation: The first non-whitespace character is '-', which is the minus sign. Then take as many numerical digits as possible, which gets 42.
Example 3:
Input: str = "4193 with words"
Output: 4193
Explanation: Conversion stops at digit '3' as the next character is not a numerical digit.
Example 4:
Input: str = "words and 987"
Output: 0
Explanation: The first non-whitespace character is 'w', which is not a numerical digit or a +/- sign. Therefore no valid conversion could be performed.
Example 5:
Input: str = "-91283472332"
Output: -2147483648
Explanation: The number "-91283472332" is out of the range of a 32-bit signed integer. Therefore INT_MIN (−2^31) is returned.
Solution 1 :
From the problem statement and examples, it is clear that we only want to convert those strings which starts either from <whitespace>, - , + or numbers 0,1,2,3,4,5,6,7,8,9 and we also don’t care about the non-number characters after the number characters.
Approach
This is a very straightforward problem which can be easily solved with the following steps -
-
Check if the string is null or empty string. If it is, return
0. -
Remove all the leading
whitespacesfrom the given string (if any). -
If the string has
-or+character at the start, we will keep it stored in a boolean flag. -
Loop for each character in the remaining string if and only if they are from the set
[0,1,2,3,4,5,6,7,8,9]. -
Store the result after each iteration in a variable number.
-
Check if the resultant number is less than
-231or more than231 - 1and return the result accordingly. -
Else return the calculated number as result.
Implementation
public class StringToInteger {
private static int myAtoi(String str) {
// Base condition
if (str == null || str.length() < 1) {
return 0;
}
// MAX and MIN values for integers
final int INT_MAX = 2147483647;
final int INT_MIN = -2147483648;
// Trimmed string
str = str.replaceAll("^\\s+", "");
// Counter
int i = 0;
// Flag to indicate if the number is negative
boolean isNegative = str.startsWith("-");
// Flag to indicate if the number is positive
boolean isPositive = str.startsWith("+");
if (isNegative) {
i++;
} else if (isPositive) {
i++;
}
// This will store the converted number
double number = 0;
// Loop for each numeric character in the string iff numeric characters are leading
// characters in the string
while (i < str.length() && str.charAt(i) >= '0' && str.charAt(i) <= '9') {
number = number * 10 + (str.charAt(i) - '0');
i++;
}
// Give back the sign to the converted number
number = isNegative ? -number : number;
if (number < INT_MIN) {
return INT_MIN;
}
if (number > INT_MAX) {
return INT_MAX;
}
return (int) number;
}
}
Complexity Analysis
Time Complexity : Since we are going through the entire number digit by digit, the time complexity should be O(log10n). The reason behind log10 is because we are dealing with integers which are base 10.
Space Complexity : We are not using any data structure for interim operations, therefore, the space complexity is O(1).
Solution 2 :
Implementation
public class Solution {
public int myAtoi(String str) {
str = str.trim();
if (str.isEmpty())
return 0;
int sign = 1; int i = 0;
if (str.charAt(0) == '-' || str.charAt(0) == '+'){
sign = (str.charAt(0) == '-')? -1 : 1;
if (str.length() < 2 || !Character.isDigit(str.charAt(1))) {
return 0;
}
i++;
}
int n = 0;
while (i < str.length()) {
if (Character.isDigit(str.charAt(i))) {
int d = str.charAt(i) - '0';
if (n > (Integer.MAX_VALUE - d) / 10) { //Detect the integer overflow.
n = (sign == -1)? Integer.MIN_VALUE : Integer.MAX_VALUE;
return n;
}
n = n*10 + d;
} else {
break;
}
i++;
}
return sign * n;
}
}
Solution 3 : StringBuilder
Implementation
class Solution {
public int myAtoi(String str) {
StringBuilder s = new StringBuilder();
for (Character c : str.toCharArray()) {
if (s.length() == 0 && c == ' ') {
// Ignore white space before numbers or word
continue;
} else if ((c == '-' || c == '+') && s.length() == 0) {
// Append only one sign
s.append(c);
} else if (c != ' ' && Character.isDigit(c)) {
// Append only valid numbers
s.append(c);
} else {
// If space or letter is encountered break out of loop
break;
}
}
return convertString(s.toString());
}
public int convertString(String s) {
int result = 0;
// If string is empty or only contains a sign, skip
if (!s.isEmpty() && !s.equals("-") && !s.equals("+")) {
try {
// Will throw an error if string is large or smaller than possible max/min integer values
result = Integer.parseInt(s);
}
catch(Exception e) {
if (s.charAt(0) == '-'){
result = Integer.MIN_VALUE;
} else {
result = Integer.MAX_VALUE;
}
}
}
return result;
}
}
Remove Duplicate Letters
Given a string s, remove duplicate letters so that every letter appears once and only once. You must make sure your result is the smallest in lexicographical order among all possible results.
Example 1:
Input: s = "bcabc"
Output: "abc"
Example 2:
Input: s = "cbacdcbc"
Output: "acdb"
Constraints:
-
1 <= s.length <= 104 -
sconsists oflowercase Englishletters.
Solution 1 : Greedy - Solving Letter by Letter
Algorithm
We use idea number one from the intuition. In each iteration, we determine leftmost letter in our solution. This will be the smallest character such that its suffix contains at least one copy of every character in the string. We determine the rest of our answer by recursively calling the function on the suffix we generate from the original string (leftmost letter is removed).
Implementation
public class Solution {
public String removeDuplicateLetters(String s) {
// find pos - the index of the leftmost letter in our solution
// we create a counter and end the iteration once the suffix doesn't have each unique character
// pos will be the index of the smallest character we encounter before the iteration ends
int[] cnt = new int[26];
int pos = 0;
for (int i = 0; i < s.length(); i++) cnt[s.charAt(i) - 'a']++;
for (int i = 0; i < s.length(); i++) {
if (s.charAt(i) < s.charAt(pos)) pos = i;
if (--cnt[s.charAt(i) - 'a'] == 0) break;
}
// our answer is the leftmost letter plus the recursive call on the remainder of the string
// note that we have to get rid of further occurrences of s[pos] to ensure that there are no duplicates
return s.length() == 0 ? "" : s.charAt(pos) + removeDuplicateLetters(s.substring(pos + 1).replaceAll("" + s.charAt(pos), ""));
}
}
Complexity Analysis
Time complexity : O(N). Each recursive call will take O(N). The number of recursive calls is bounded by a constant (26 letters in the alphabet), so we have O(N)∗C=O(N).
Space complexity : O(N). Each time we slice the string we’re creating a new one (strings are immutable). The number of slices is bound by a constant, so we have O(N)∗C=O(N).
Solution 2 : Greedy - Solving with Stack
Implementation
class Solution {
public String removeDuplicateLetters(String s) {
Stack<Character> stack = new Stack<>();
// this lets us keep track of what's in our solution in O(1) time
HashSet<Character> seen = new HashSet<>();
// this will let us know if there are any more instances of s[i] left in s
HashMap<Character, Integer> last_occurrence = new HashMap<>();
for(int i = 0; i < s.length(); i++) last_occurrence.put(s.charAt(i), i);
for(int i = 0; i < s.length(); i++){
char c = s.charAt(i);
// we can only try to add c if it's not already in our solution
// this is to maintain only one of each character
if (!seen.contains(c)){
// if the last letter in our solution:
// 1. exists
// 2. is greater than c so removing it will make the string smaller
// 3. it's not the last occurrence
// we remove it from the solution to keep the solution optimal
while(!stack.isEmpty() && c < stack.peek() && last_occurrence.get(stack.peek()) > i){
seen.remove(stack.pop());
}
seen.add(c);
stack.push(c);
}
}
StringBuilder sb = new StringBuilder(stack.size());
for (Character c : stack) sb.append(c.charValue());
return sb.toString();
}
}
Complexity Analysis
Time complexity : O(N).
Space complexity : O(1).
Search Suggestions System
You are given an array of strings products and a string searchWord.
Design a system that suggests at most three product names from products after each character of searchWord is typed. Suggested products should have common prefix with searchWord. If there are more than three products with a common prefix return the three lexicographically minimums products.
Return a list of lists of the suggested products after each character of searchWord is typed.
Example 1:
Input: products = ["mobile","mouse","moneypot","monitor","mousepad"], searchWord = "mouse"
Output: [["mobile","moneypot","monitor"],["mobile","moneypot","monitor"],["mouse","mousepad"],["mouse","mousepad"],["mouse","mousepad"]]
Explanation: products sorted lexicographically = ["mobile","moneypot","monitor","mouse","mousepad"].
After typing m and mo all products match and we show user ["mobile","moneypot","monitor"].
After typing mou, mous and mouse the system suggests ["mouse","mousepad"].
Example2:
Input: products = ["havana"], searchWord = "havana"
Output: [["havana"],["havana"],["havana"],["havana"],["havana"],["havana"]]
Explanation: The only word "havana" will be always suggested while typing the search word.
Constraints:
-
1 <= products.length <= 1000 -
1 <= products[i].length <= 3000 -
1 <= sum(products[i].length) <= 2 * 104 -
All the strings of
productsare unique. -
products[i]consists of lowercase English letters. -
1 <= searchWord.length <= 1000 -
searchWordconsists of lowercase English letters.
Solution 1 : Binary Search
Intuition
Since the question asks for the result in a sorted order, let’s start with sorting products. An advantage that comes with sorting is Binary Search, we can binary search for the prefix. Once we locate the first match of prefix, all we need to do is to add the next 3 words into the result (if there are any), since we sorted the words beforehand.
Algorithm
-
Sort the input
products. -
Iterate each character of the
searchWordadding it to theprefixto search for. -
After adding the current character to the
prefixbinary search for theprefixin the input. -
Add next 3 strings from the current binary search
startindex till theprefixremains same. -
Another optimization that can be done is reducing the binary search space to current
startindex (This is due to the fact that adding more characters to the prefix will make the next search result’s index be at least > current search’s index).
Implementation
class Solution {
// Equivalent code for lower_bound in Java
int lower_bound(String[] products, int start, String word) {
int i = start, j = products.length, mid;
while (i < j) {
mid = (i + j) / 2;
if (products[mid].compareTo(word) >= 0)
j = mid;
else
i = mid + 1;
}
return i;
}
public
List<List<String>> suggestedProducts(String[] products, String searchWord) {
Arrays.sort(products);
List<List<String>> result = new ArrayList<>();
int start = 0, bsStart = 0, n = products.length;
String prefix = new String();
for (char c : searchWord.toCharArray()) {
prefix += c;
// Get the starting index of word starting with `prefix`.
start = lower_bound(products, bsStart, prefix);
// Add empty vector to result.
result.add(new ArrayList<>());
// Add the words with the same prefix to the result.
// Loop runs until `i` reaches the end of input or 3 times or till the
// prefix is same for `products[i]` Whichever comes first.
for (int i = start; i < Math.min(start + 3, n); i++) {
if (products[i].length() < prefix.length() || !products[i].substring(0, prefix.length()).equals(prefix))
break;
result.get(result.size() - 1).add(products[i]);
}
// Reduce the size of elements to binary search on since we know
bsStart = Math.abs(start);
}
return result;
}
}
Complexity Analysis
Time complexity : O(nlog(n))+O(mlog(n)). Where n is the length of products and m is the length of the search word. Here we treat string comparison in sorting as O(1). O(nlog(n)) comes from the sorting and O(mlog(n)) comes from running binary search on products m times.
- In Java there is an additional complexity of O(m^2) due to Strings being immutable, here m is the length of
searchWord.
Space complexity : Varies between O(1)O(1)O(1) and O(n) where n is the length of products, as it depends on the implementation used for sorting. We ignore the space required for output as it does not affect the algorithm’s space complexity.
Solution 2 : Trie + DFS
Algorithm
-
Create a Trie from the given
productsinput. -
Iterate each character of the
searchWordadding it to theprefixto search for. -
After adding the current character to the
prefixtraverse the trie pointer to the node representingprefix. -
Now traverse the tree from curr pointer in a preorder fashion and record whenever we encounter a complete word.
-
Limit the result to 3 and return dfs once reached this limit.
-
Add the words to the final result.
Implementation
// Custom class Trie with function to get 3 words starting with given prefix
class Trie {
// Node definition of a trie
class Node {
boolean isWord = false;
List<Node> children = Arrays.asList(new Node[26]);
};
Node Root, curr;
List<String> resultBuffer;
// Runs a DFS on trie starting with given prefix and adds all the words in the resultBuffer, limiting result size to 3
void dfsWithPrefix(Node curr, String word) {
if (resultBuffer.size() == 3)
return;
if (curr.isWord)
resultBuffer.add(word);
// Run DFS on all possible paths.
for (char c = 'a'; c <= 'z'; c++)
if (curr.children.get(c - 'a') != null)
dfsWithPrefix(curr.children.get(c - 'a'), word + c);
}
Trie() {
Root = new Node();
}
// Inserts the string in trie.
void insert(String s) {
// Points curr to the root of trie.
curr = Root;
for (char c : s.toCharArray()) {
if (curr.children.get(c - 'a') == null)
curr.children.set(c - 'a', new Node());
curr = curr.children.get(c - 'a');
}
// Mark this node as a completed word.
curr.isWord = true;
}
List<String> getWordsStartingWith(String prefix) {
curr = Root;
resultBuffer = new ArrayList<String>();
// Move curr to the end of prefix in its trie representation.
for (char c : prefix.toCharArray()) {
if (curr.children.get(c - 'a') == null)
return resultBuffer;
curr = curr.children.get(c - 'a');
}
dfsWithPrefix(curr, prefix);
return resultBuffer;
}
};
class Solution {
List<List<String>> suggestedProducts(String[] products,
String searchWord) {
Trie trie = new Trie();
List<List<String>> result = new ArrayList<>();
// Add all words to trie.
for (String w : products)
trie.insert(w);
String prefix = new String();
for (char c : searchWord.toCharArray()) {
prefix += c;
result.add(trie.getWordsStartingWith(prefix));
}
return result;
}
};
Complexity Analysis
Time complexity : O(M) to build the trie where M is total number of characters in products For each prefix we find its representative node in O(len(prefix)) and dfs to find at most 3 words which is an O(1) operation. Thus the overall complexity is dominated by the time required to build the trie.
- In Java there is an additional complexity of O(m^2) due to Strings being immutable, here m is the length of
searchWord.
Space complexity : O(26n)=O. Here n is the number of nodes in the trie. 26 is the alphabet size. Space required for output is O(m) where m is the length of the search word.
Decode Ways
A message containing letters from A-Z can be encoded into numbers using the following mapping:
'A' -> "1"
'B' -> "2"
...
'Z' -> "26"
To decode an encoded message, all the digits must be grouped then mapped back into letters using the reverse of the mapping above (there may be multiple ways). For example, “11106” can be mapped into:
-
AAJFwith the grouping(1 1 10 6) -
KJFwith the grouping(11 10 6) -
Note that the grouping
(1 11 06)is invalid because06cannot be mapped into ‘F’ since6is different from06.
Given a string s containing only digits, return the number of ways to decode it.
The test cases are generated so that the answer fits in a 32-bit integer.
Example 1:
Input: s = "12"
Output: 2
Explanation: "12" could be decoded as "AB" (1 2) or "L" (12).
Example 2:
Input: s = "226"
Output: 3
Explanation: "226" could be decoded as "BZ" (2 26), "VF" (22 6), or "BBF" (2 2 6).
Example 3:
Input: s = "06"
Output: 0
Explanation: "06" cannot be mapped to "F" because of the leading zero ("6" is different from "06").
Constraints:
-
1 <= s.length <= 100 -
scontains only digits and may contain leading zero(s).
Solution 1 : Recursive Approach with Memoization
Algorithm
-
Enter recursion with the given string i.e. start with index 0.
-
For the terminating case of the recursion we check for the end of the string. If we have reached the end of the string we return
1. -
Every time we enter recursion it’s for a substring of the original string. For any recursion if the first character is
0then terminate that path by returning0. Thus this path won’t contribute to the number of ways. -
Memoization helps to reduce the complexity which would otherwise be exponential. We check the dictionary
memoto see if the result for the given substring already exists. -
If the result is already in
memowe return the result. Otherwise the number of ways for the given string is determined by making a recursive call to the function withindex + 1for next substring string andindex + 2after checking for valid 2-digit decode. The result is also stored inmemowith key as current index, for saving for future overlapping subproblems.
Implementation
class Solution {
Map<Integer, Integer> memo = new HashMap<>();
public int numDecodings(String s) {
return recursiveWithMemo(0, s);
}
private int recursiveWithMemo(int index, String str) {
// Have we already seen this substring?
if (memo.containsKey(index)) {
return memo.get(index);
}
// If you reach the end of the string
// Return 1 for success.
if (index == str.length()) {
return 1;
}
// If the string starts with a zero, it can't be decoded
if (str.charAt(index) == '0') {
return 0;
}
if (index == str.length() - 1) {
return 1;
}
int ans = recursiveWithMemo(index + 1, str);
if (Integer.parseInt(str.substring(index, index + 2)) <= 26) {
ans += recursiveWithMemo(index + 2, str);
}
// Save for memoization
memo.put(index, ans);
return ans;
}
}
Complexity Analysis
Time Complexity: O(N), where N is length of the string. Memoization helps in pruning the recursion tree and hence decoding for an index only once. Thus this solution is linear time complexity.
Space Complexity: O(N). The dictionary used for memoization would take the space equal to the length of the string. There would be an entry for each index value. The recursion stack would also be equal to the length of the string.
Solution 2 : Iterative Approach
Algorithm
-
If the string s is empty or null we return the result as
0. -
Initialize dp array.
dp[0] = 1to provide the baton to be passed. -
If the first character of the string is zero then no decode is possible hence initialize
dp[1]to0, otherwise the first character is valid to pass on the baton,dp[1] = 1. -
Iterate the dp array starting at index 2. The index i of dp is the i-th character of the string s, that is character at index
i-1ofs. -
We check if valid single digit decode is possible. This just means the character at index
s[i-1]is non-zero. Since we do not have a decoding for zero. If the valid single digit decoding is possible then we add dp[i-1] to dp[i]. Since all the ways up to (i-1)-th character now lead up to i-th character too. -
We check if valid two digit decode is possible. This means the substring
s[i-2]s[i-1]is between10to26. If the valid two digit decoding is possible then we adddp[i-2]todp[i]. -
Once we reach the end of the
dparray we would have the number of ways of decoding strings.
Implementation
class Solution {
public int numDecodings(String s) {
// DP array to store the subproblem results
int[] dp = new int[s.length() + 1];
dp[0] = 1;
// Ways to decode a string of size 1 is 1. Unless the string is '0'.
// '0' doesn't have a single digit decode.
dp[1] = s.charAt(0) == '0' ? 0 : 1;
for(int i = 2; i < dp.length; i++) {
// Check if successful single digit decode is possible.
if (s.charAt(i - 1) != '0') {
dp[i] = dp[i - 1];
}
// Check if successful two digit decode is possible.
int twoDigit = Integer.valueOf(s.substring(i - 2, i));
if (twoDigit >= 10 && twoDigit <= 26) {
dp[i] += dp[i - 2];
}
}
return dp[s.length()];
}
}
Complexity Analysis
Time Complexity: O(N), where N is length of the string. We iterate the length of dp array which is N+1.
Space Complexity: O(N). The length of the DP array.
Solution 3 : Iterative, Constant Space
Implementation
class Solution {
public int numDecodings(String s) {
if (s.charAt(0) == '0') {
return 0;
}
int n = s.length();
int twoBack = 1;
int oneBack = 1;
for (int i = 1; i < n; i++) {
int current = 0;
if (s.charAt(i) != '0') {
current = oneBack;
}
int twoDigit = Integer.parseInt(s.substring(i - 1, i + 1));
if (twoDigit >= 10 && twoDigit <= 26) {
current += twoBack;
}
twoBack = oneBack;
oneBack = current;
}
return oneBack;
}
}
Complexity Analysis
Time Complexity: O(N), where N is length of the string. We’re essentially doing the same work as what we were in Solution 2, except this time we’re throwing away calculation results when we no longer need them.
Space Complexity: O(1). Instead of a dp array, we’re simply using two variables.