Collection Framework
Table of contents
- ArrayList
- HashMap
- HashMap Internal working 1
- HashMap Internal working 2
- How put() method of HashMap works internally
- How HashMap get() method works internally
- When null Key is inserted in a HashMap
- HashMap implementation changes in Java 8
- Interal working of put() and get() methods of HashMap
- HashMap collisions
- equals and hashCode method in HashMap when the key is a custom class
- Does Hashmap allow duplicate keys ?
- ConcurrentHashMap
- HashSet class
- TreeMap
- TreeSet
- fail-safe and fail-fast iterators
- For more information
Collection framework represents an architecture to store and manipulate a group of objects. All the classes and interfaces of this framework are present in java.util package.
Some points:
- Iterable interface is the root interface for all collection classes, it has one abstract method iterator()
- Collection interface extends the Iterable interface
ArrayList
- An ArrayList is a re-sizable array, also called a dynamic array. It grows its size to accommodate new elements and shrinks the size when the elements are removed.
- ArrayList internally uses an array to store the elements. Just like arrays, It allows you to retrieve the elements by their index.
- ArrayList allows duplicate and null values.
- ArrayList is an ordered collection. It maintains the insertion order of the elements.
- You cannot create an ArrayList of primitive types like int, char etc. You need to use boxed types like Integer, Character, Boolean etc.
- ArrayList is not synchronized. If multiple threads try to modify an ArrayList at the same time, then the final outcome will be non-deterministic. You must explicitly synchronize access to an ArrayList if multiple threads are gonna modify it.
Accessing elements
- check if an ArrayList is empty using the
isEmpty()method. - find the size of an ArrayList using the
size()method. - access the element at a particular index in an ArrayList using the
get()method. - modify the element at a particular index in an ArrayList using the
set()method.
Removing elements
- remove the element at a given index in an ArrayList using
remove(int index) - remove an element from an ArrayList using
remove(Object o) - remove all the elements from an ArrayList that exist in a given collection using
removeAll() - remove all the elements matching a given predicate using
removeIf() - clear an ArrayList using
clear()
Iterating over an ArrayList
- Java 8 forEach and lambda expression.
- iterator().
- iterator() and Java 8 forEachRemaining() method.
- listIterator().
- Simple for-each loop.
- for loop with index.
Searching for elements in an ArrayList
-
Check if an ArrayList contains a given element contains() -
Find the index of the first occurrence of an element in an ArrayList indexOf() -
Find the index of the last occurrence of an element in an ArrayList lastIndexOf()
Sorting an ArrayList
- Sort an ArrayList using
Collections.sort()method. - Sort an ArrayList using
ArrayList.sort()method. - Sort an ArrayList of user defined objects with a custom comparator.
HashMap
HashMap class implements the Map interface and it stores data in key, value pairs. HashMap provides constant time performance for its get() and put() operations, assuming the equals and hashcode method has been implemented properly, so that elements can be distributed correctly among the buckets.
Some points to remember:
- Keys should be unique in HashMap, if you try to insert the duplicate key, then it will override the corresponding key’s value
- HashMap may have one null key and multiple null values
- HashMap does not guarantee the insertion order (if you want to maintain the insertion order, use LinkedHashMap class)
- HashMap is not synchronized
- HashMap uses an inner class Node<K, V> for storing map entries
- Hashmap has a default initial capacity of 16, which means it has 16 buckets or bins to store map entries, each bucket is a singly linked list. The default load factor in HashMap is 0.75
- Load factor is that threshold value which when crossed will double the hashmap’s capacity i.e. when you add 13th element in hashmap, the capacity will increase from 16 to 32
HashMap Internal working 1
HashMap is a data structure that uses a hash function to map keys to their values. The internal working of HashMap in Java involves the following steps:
Hashcode Calculation
When a key is added to the HashMap, its hashcode is calculated using the hashCode() method. This hashcode is then used to determine the index of the bucket where the key-value pair will be stored.
Buckets
The HashMap is divided into an array of buckets, where each bucket is a linked list of elements. The number of buckets is determined by the initial capacity of the HashMap.
Resizing
If the number of elements in the HashMap exceeds the capacity of the buckets, the HashMap is resized to accommodate more elements. This is done by creating a new array of buckets with a larger capacity and rehashing all the elements to their new locations.
Collision Resolution
When two or more keys have the same hashcode, they are stored in the same bucket. This is known as a collision. HashMap uses a technique called open addressing to resolve collisions. In open addressing, if a collision occurs, the next available bucket is checked for an empty slot to store the key-value pair.
Rehashing
When a key-value pair is added to the HashMap, the key’s hashcode is used to determine the index of the bucket where it should be stored. If the bucket is already full, the HashMap checks the next available bucket, and so on, until an empty slot is found.
Iteration
To iterate over the elements of a HashMap, the HashMap’s entrySet() method is used to return a Set view of the mappings contained in this map. The set is backed by the map, so changes to the map are reflected in the set, and vice-versa.
Load Factor
HashMap uses a load factor to determine when to resize the map. The load factor is a measure of how full the map is allowed to get before its capacity is automatically increased. The default load factor of HashMap is 0.75, meaning that the map can be filled to 75% of its capacity before it is resized.
Concurrency
HashMap is not thread-safe and it is not intended for use in concurrent environments. If multiple threads access a HashMap concurrently and at least one of the threads modifies the map, it must be synchronized externally.
Performance
HashMap provides constant-time performance for basic operations like get and put, assuming that the hash function distributes the keys evenly across the buckets. However, if the hash function is not good, the performance of the HashMap can degrade to linear time. Also, if the number of collisions is high, the performance of HashMap can also degrade.
Null keys and values
HashMap allows null keys and values. However, it is important to note that only one null key is allowed in the map and if a null key is used, it will always be stored at index 0. Also, if multiple null values are added to the map, they will be stored in the same bucket.
HashMap implementation in the JDK
HashMap is implemented in the JDK using an array of Entry objects, where each Entry object represents a key-value pair. Each Entry object also contains a reference to the next Entry object in the same bucket, in case of collisions.
In summary, It uses a hash function to map keys to their values, and it uses open addressing to resolve collisions. HashMap provides constant-time performance for basic operations, but its performance can degrade if the hash function is not good or if there are a large number of collisions. It is important to understand the internal working of HashMap to effectively use it in your code and to optimize its performance.
HashMap Internal working 2
- HashMap works on the principal of hashing.
- HashMap in Java uses the
hashCode()method to calculate a hash value. Hash value is calculated using the key object. This hash value is used to find the correct bucket where Entry object will be stored. - HashMap uses the
equals()method to find the correct key whose value is to be retrieved in case of get() and to find if that key already exists or not in case of put(). - With in the internal implementation of HashMap hashing collision means more than one key having the same hash value, in that case Entry objects are stored as a linked-list with in a same bucket.
- With in a bucket values are stored as Entry objects which contain both key and value.
- In Java 8 hash elements use balanced trees instead of linked lists after a certain threshold is reached while storing values. This improves the worst case performance from O(n) to O(log n).
HashMap class in Java internally uses an array called table of type Node to store the elements which is defined in the HashMap class as-
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
Node is defined as a static class with in a Hashmap.
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
For each element 4 things are stored in the fields-
- hash- For storing Hashcode calculated using the key.
- key- For holding key of the element.
- value- For storing value of the element.
- next- To store reference to the next node when a bucket has more than one element and a linkedlist is formed with in a bucket to store elements.
Objects are stored internally in table array of the HashMap class.
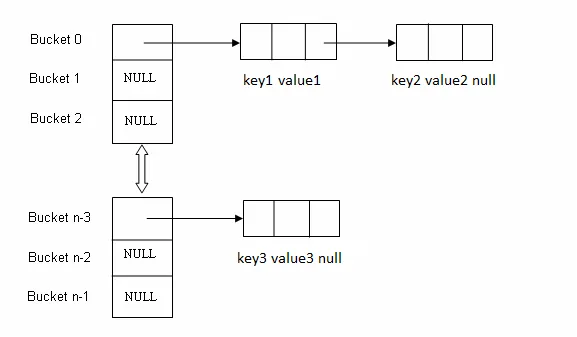
How put() method of HashMap works internally
There are 3 steps in the internal implementation of HashMap put() method-
- Using
hashCode()method, hash value will be calculated. In which bucket particular entry will be stored is ascertained using that hash. equals()method is used to find if such a key already exists in that bucket, if not found then a new node is created with the map entry and stored within the same bucket. A linked-list is used to store those nodes.- If
equals()method returns true, it means that the key already exists in the bucket. In that case, the new value will overwrite the old value for the matched key.
How HashMap get() method works internally
Using the key (passed in the get() method) hash value will be calculated to determine the bucket where that Entry object is stored, in case there are more than one Entry object with in the same bucket (stored as a linked-list) equals() method will be used to find out the correct key. As soon as the matching key is found get() method will return the value object stored in the Entry object.
When null Key is inserted in a HashMap
HashMap in Java also allows null as key, though there can only be one null key in HashMap. While storing the Entry object HashMap implementation checks if the key is null, in case key is null, it is always mapped to bucket 0, as hash is not calculated for null keys.
HashMap implementation changes in Java 8
HashMap implementation in Java provides constant time performance O(1) for get() and put() methods but that is in the ideal case when the Hash function distributes the objects evenly among the buckets.
But the performance may worsen in the case hashCode() used is not proper and there are lots of hash collisions. As we know now that in case of hash collision entry objects are stored as a node in a linked-list and equals() method is used to compare keys. That comparison to find the correct key with in a linked-list is a linear operation so in a worst case scenario the complexity becomes O(n).
To fix this issue in Java 8 hash elements use balanced trees instead of linked lists after a certain threshold is reached. Which means HashMap starts with storing Entry objects in linked list but after the number of items in a hash becomes larger than a certain threshold, the hash changes from using a linked list to a balanced tree, this improves the worst case performance from O(n) to O(log n).
Interal working of put() and get() methods of HashMap
-
put() method internal working: When you call map.put(key,value), the below things happens:
- Key’s hashCode() method is called
- Hashmap has an internal hash function which takes the key’s hashCode and it calculates the bucket index
- If there is no element present at that bucket index, our <key, value> pair along with hash is stored at that bucket
- But if there is an element present at the bucket index, then key’s hashCode is used to check whether this key is already present with the same hashCode or not.
If there is key with same hashCode, then equals method is used on the key. If equals method returns true, then the key’s previous value is replaced with the new value otherwise a new entry is appended to the linked list.
-
get() method internal working: When you call map.get(key), the below things happen:
- Key’s hashCode() method is called
- Hash function uses this hashCode to calculate the index, just like in put method
- Now the key of element stored in bucket is compared with the passed key using equals() method, if both are equals, value is returned otherwise the next element is checked if it exists.
See HashMap’s Javadoc: Default capacity:
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
Load factor:
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
Node class:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash ;
"final K key ;
V value ;
Node<K,V> next ;
Node(int hash , K key , V value , Node<K,V> next ) {
this .hash = hash ;
this .key = key ;
this .value = value ;
this .next = next ;
}
Internal Hash function:
static final int hash(Object key ) {
int h ;
return (key == null ) ? 0 : (h = key .hashCode()) ^ (h >>> 16);
}
Internal Data structure used by HashMap to hold buckets:
transient Node<K,V>[] table ;
HashMap’s default constructor:
/**
* Constructs an empty <tt> HashMap </tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this .loadFactor = DEFAULT_LOAD_FACTOR ; // all other fields defaulted
}
So, to conclude, Hashmap internally uses an array of Nodes named as table where each Node contains the calculated hash value, the key-value pair and the address to the next node.
HashMap collisions
It is possible that multiple keys will make the hash function generate the same index, this is called a collision. It happens because of poor hashcode method implementation.
One collision handling technique is called Chaining. Since every element in the array is a linked list, the keys which have the same hash function will be appended to the linked list.
- Performance improvement in Java 8 : It is possible that due to multiple collisions, the linked list size has become very large, and as we know, searching in a linked list is O(n), it will impact the constant time performance of hashmap’s get() method. So, in Java 8, if the linked list size becomes more than 8, the linked list is converted to a binary search tree which will give a better time complexity of O(log n). ```java /**
- The bin count threshold for using a tree rather than list for a
- bin. Bins are converted to trees when adding an element to a” “* bin with at least this many nodes. The value must be greater
- than 2 and should be at least 8 to mesh with assumptions in
- tree removal about conversion back to plain bins upon
- shrinkage. */ static final int TREEIFY_THRESHOLD = 8;
Program showing the default capacity:
```java
import java.lang.reflect.Field;
import java.util.HashMap;
public class TestHashMap {
public static void main(String[] args) throws Exception {
HashMap<String, String> map = new HashMap<>();
map.put("name", "Mike");
Field tableField = HashMap.class.getDeclaredField("table");
tableField.setAccessible(true);
Object[] table = (Object[]) tableField.get(map);
System.out.print("hashmap capacity: ");
System.out.print(table == null ? 0 : table.length);
System.out.println("\nhashmap size:" + map.size());
}
}
Output:
hashmap capacity: 16
hashmap size: 1
Program showing that hashmap’s capacity gets doubled after load factor’s threshold value breaches :
import java.lang.reflect.Field;
import java.util.HashMap;
class Employee {
private int age;
public Employee(int age) {
this.age = age;
}
}
public class TestHashMap {
public static void main(String[] args) throws Exception {
HashMap<Employee, String> map = new HashMap<>();
for(int i=1;i<13;i++) {
map.put(new Employee(i), "Hello " + i);
}
Field tableField = HashMap.class.getDeclaredField("table");
tableField.setAccessible(true);
Object[] table = (Object[]) tableField.get(map);
System.out.print("hashmap capacity: ");
System.out.print(table == null ? 0 : table.length);
System.out.println("\nhashmap size:" + map.size());
}
}
Output:
hashmap capacity: 16
hashmap size: 12
Change the for loop condition from i<13 to i<=13, see below:
import java.lang.reflect.Field;
import java.util.HashMap;
class Employee {
private int age;
public Employee(int age) {
this.age = age;
}
}
public class TestHashMap {
public static void main(String[] args) throws Exception {
HashMap<Employee, String> map = new HashMap<>();
for(int i=1;i<13;i++) {
map.put(new Employee(i), "Hello " + i);
}
Field tableField = HashMap.class.getDeclaredField("table");
tableField.setAccessible(true);
Object[] table = (Object[]) tableField.get(map);
System.out.print("hashmap capacity: ");
System.out.print(table == null ? 0 : table.length);
System.out.println("\nhashmap size:" + map.size());
}
}
Output:
hashmap capacity: 32
hashmap size: 13
equals and hashCode method in HashMap when the key is a custom class
equals and hashCode methods are called when we store and retrieve values from hashmap.
if in your custom class, you are not implementing equals() and hashCode(), then the Object class equals() and hashCode() will be called, and the contract between these 2 methods. It says when 2 objects are equal according to equals() method, then their hashCode must be same, reverse may not be true.
- Scenario 1: when custom class does not implement both equals and hashCode methods
public class Employee { private String name; private int age; public Employee(String name, int age) { this.name = name; this.age = age; } }Here,
Employeeclass has not givenequals()andhashCode()method implementation, so Object’s classequals()andhashCode()methods will be used when we use thisEmployeeclass as hashmap’s key, and remember, equals() method of Object class compares the reference.
TestHashMap.java:
import java.util.HashMap;
import java.util.Map;
public class TestHashMap {
public static void main(String[] args) {
Map<Employee, Integer> map = new HashMap<>();
Employee e1 = new Employee("Mike", 15);
Employee e2 = new Employee("Mike", 15);
Employee e3 = new Employee("John", 20);
Employee e4 = e3;
System.out.println("e1 hashcode: " + e1.hashCode());
System.out.println("e2 hashcode: " + e2.hashCode());
System.out.println("e3 hashcode: " + e3.hashCode());
System.out.println("e4 hashcode: " + e4.hashCode());
System.out.println("e1 equals e2: " + e1.equals(e2));
System.out.println("e3 equals e4: " + e3.equals(e4));
map.put(e1, 100);
map.put(e2, 200);
map.put(e3, 300);
map.put(e4, 400);
System.out.println(map.get(e1));
System.out.println(map.get(e2));
System.out.println(map.get(e3));
System.out.println(map.get(e4));
System.out.println("hashmap size: " + map.size());
}
}
Output:
e1 hashcode: 1324119927
e2 hashcode: 999966131
e3 hashcode: 1989780873
e4 hashcode: 1989780873
e1 equals e2: false
e3 equals e4: true
100
200
400
400
hashmap size: 3
Here, Employee objects e1 and e2 are same but they are both inserted in the HashMap because both are created using new keyword and holding a different reference, and as the Object’s equals() method checks reference, they both are unique. And as for objects e3 and e4, they both are pointing to same reference (e4 = e3), so they are equal according to Object’s equals() method hence the value of e3 which was 300 gets replaced with the value 400 of the same key e4, and finally size of HashMap is 3.
- Scenario 2: when only equals() method is implemented by Employee class
public class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
import java.util.HashMap;
import java.util.Map;
public class TestHashMap {
public static void main(String[] args) {
Map<Employee, Integer> map = new HashMap<>();
Employee e1 = new Employee("Mike", 15);
Employee e2 = new Employee("Mike", 15);
Employee e3 = new Employee("John", 20);
Employee e4 = e3;
System.out.println("e1 hashcode: " + e1.hashCode());
System.out.println("e2 hashcode: " + e2.hashCode());
System.out.println("e3 hashcode: " + e3.hashCode());
System.out.println("e4 hashcode: " + e4.hashCode());
System.out.println("e1 equals e2: " + e1.equals(e2));
System.out.println("e3 equals e4: " + e3.equals(e4));
map.put(e1, 100);
map.put(e2, 200);
map.put(e3, 300);
map.put(e4, 400);
System.out.println(map.get(e1));
System.out.println(map.get(e2));
System.out.println(map.get(e3));
System.out.println(map.get(e4));
System.out.println("hashmap size: " + map.size());
}
}
Let’s see the output:
e1 hashcode: 1324119927
e2 hashcode: 999966131
e3 hashcode: 1989780873
e4 hashcode: 1989780873
e1 equals e2: true
e3 equals e4: true
100
200
400
400
hashmap size: 3
Well, nothing’s changed here. Because even though e1 and e2 are equal according to our newly implemented equals() method, they still have different hashCode as the Object’s class hashCode() is used. So the equals and hashCode contract is not followed and both e1, e2 got inserted in HashMap.
- Scenario 3: when only hashCode() method is implemented:
public class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
}
Let’s run our TestHashMap class again and see the output:
e1 hashcode: 2399656
e2 hashcode: 2399656
e3 hashcode: 2316120
e4 hashcode: 2316120
e1 equals e2: false
e3 equals e4: true
100
200
400
400
hashmap size: 3
Well, now we have same hashCode for e1 and e2, but Object’s equals method still checks the references and as references are different, both are not equal and are inserted in the hashmap.
- Scenario 4: When both equals and hashCode are implemented properly:
public class Employee {
private String name;
private int age;
public Employee(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Employee other = (Employee) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
}
Output:
e1 hashcode: 2399656
e2 hashcode: 2399656
e3 hashcode: 2316120
e4 hashcode: 2316120
e1 equals e2: true
e3 equals e4: true
200
200
400
400
hashmap size: 2
Here, both e1 and e2 are equals as we are comparing the contents of them in our equals() method, so their hashCodes must be same, which they are. So value of e1 which was 100 got replaced by 200, and size of hashmap is 2.
How to make a HashMap synchronized?
Collections.synchronizedMap(map);
Does Hashmap allow duplicate keys ?
No. If we attempt to add duplicate keys, it will replace the element of the corresponding keys
example -
public static void main(String[] args)
{
// This is how to declare HashMap
HashMap<Integer, String> hm = new HashMap<Integer, String>();
// Adding elements to HashMap*/
hm.put(12, "geeks");
hm.put(2, "practice");
hm.put(7, "contribute");
System.out.println("\nHashMap object output :\n\n" + hm);
// store data with duplicate key
hm.put(7, "geeks");
hm.put(12, "contribute");
System.out.println("\nAfter inserting duplicate key :\n\n" + hm);
}
Output :
{2=practice, 7=contribute, 12=geeks}
After inserting duplicate key :
{2=practice, 7=geeks, 12=contribute}
ConcurrentHashMap
ConcurrentHashMap class provides concurrent access to the map, this class is very similar to HashTable, except that ConcurrentHashMap provides better concurrency than HashTable or even synchronizedMap.
Some points to remember:
ConcurrentHashMapis internally divided into segments, by default size is 16 that means, at max 16 threads can work at a time- Unlike
HashTable, the entire map is not locked while reading/writing from the map - In
ConcurrentHashMap, concurrent threads can read the value without locking - For adding or updating the map, the lock is obtained on segment level, that means each thread can work on each segment during high concurrency
- Concurrency level defines a number, which is an estimated number of threads concurrently accessing the map
ConcurrentHashMapdoes not allow null keys or null values- put() method acquires lock on the segment
- get() method returns the most recently updated value
- iterators returned by
ConcurrentHashMapare fail-safe and never throwConcurrentModificationException
ConcurrentHashMap Internal Working
As opposed to the HashTables where every read/write operation needs to acquire the lock, there is no locking at the object level in CHM and locking is much granular at a hashmap bucket level. CHM(ConcurrentHashMap) never locks the whole Map, instead, it divides the map into segments and locking is done on these segments. CHM is separated into different regions(default-16) and locks are applied to them. When setting data in a particular segment, the lock for that segment is obtained. This means that two updates can still simultaneously execute safely if they each affect separate buckets, thus minimizing lock contention and so maximizing performance.
ConcurrentHashMap vs Synchronized HashMap
Synchronized HashMap:
- Each method is synchronized using an object level lock. So the get and put methods on synchMap acquire a lock.
- Locking the entire collection is a performance overhead. While one thread holds on to the lock, no other thread can use the collection.
ConcurrentHashMap was introduced in JDK 5.
- There is no locking at the object level,The locking is at a much finer granularity. For a ConcurrentHashMap, the locks may be at a hashmap bucket level.
- The effect of lower level locking is that you can have concurrent readers and writers which is not possible for synchronized collections. This leads to much more scalability.
- ConcurrentHashMap does not throw a ConcurrentModificationException if one thread tries to modify it while another is iterating over it.
HashSet class
HashSet is a class in Java that implements the Set Interface and it allows us to have the unique elements only. HashSet class does not maintain the insertion order of elements, if you want to maintain the insertion order, then you can use LinkedHashSet.
- Internal implementation of HashSet:
HashSet internally uses HashMap and as we know the keys are unique in hashmap, the value passed in the add() method of HashSet is stored as the key of hashmap, that is how Set maintains the unique elements.
/**
* Constructs a new, empty set; the backing <tt> HashMap </tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
private transient HashMap<E,Object> map ;
Let’s see add() method’s Javadoc:
public boolean add(E e ) {
return map .put(e , PRESENT )==null ;
}
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
So, when we call hashSet.add(element) method then
- map.put() is called where key is the element and value is the dummy value (the map.put() method internal working has already been discussed above)
- if value is added in the map then put method will return null which will be compared with null, hence returning true from hashSet.add() method indicating the element is added
- however if the element is already present in the map, then the value associated with the element will be returned which in turn will be compared with null, returning false from hashSet.add() method
set.contains() method:
public boolean contains(Object o ) {
return map .containsKey(o );
}
The passed object is given to map.containsKey() method, as the HashSet’s values are stored as the keys of internal map.
NOTE: If you are adding a custom class object inside the HashSet, do follow equals and hashCode contract.
TreeMap
TreeMap class is one of the implementation of Map interface.
Some points to remember:
- TreeMap entries are sorted based on the natural ordering of its keys. This means if we are using a custom class as the key, we have to make sure that the custom class is implementing Comparable interface
- TreeMap class also provides a constructor which takes a Comparator object, this should be used when we want to do a custom sorting
- TreeMap provides guaranteed log(n) time complexity for the methods such as containsKey(), get(), put() and remove()
- TreeMap iterator is fail-fast in nature, so any concurrent modification will result in ConcurrentModificationException
- TreeMap does not allow null keys but it allows multiple null values
- TreeMap is not synchronized, so it is not thread-safe. We can make it thread-safe by using utility method, Collections.synchronizedSortedMap(treeMap)
- TreeMap internally uses Red-Black tree based NavigableMap implementation.
Red-Black tree algorithm has the properties:
- Color of every node in the tree is either red or black.
- Root node must be Black in color.
- Red node cannot have a red color neighbor node.
-
All paths from root node to the null should consist the same number of black nodes
- Program 1: Using Wrapper class as key
import java.util.TreeMap;
public class TestTreeMap {
public static void main(String[] args) {
TreeMap<Integer, String> map = new TreeMap<>();
map.put(4, "Mike");
map.put(1, "John");
map.put(3, "Jack");
map.put(2, "Lisa");
map.forEach((k,v) -> System.out.println(k + ":" + v));
}
}
Output:
1:John
2:Lisa
3:Jack
4:Mike
Here, Integer class already implements Comparable interface, so the keys are sorted based on the Integer’s natural sorting order (ascending order).
Let’s see, when key is a custom class:
- Program 2:
import java.util.TreeMap;
class Employee {
String name;
int age;
Employee(String name, int age) {
this.name = name;
this.age = age;
}
}
public class TestTreeMap {
public static void main(String[] args) {
TreeMap<Employee, Integer> map = new TreeMap<>();
map.put(new Employee("Mike", 20), 100);
map.put(new Employee("John", 10), 500);
map.put(new Employee("Ryan", 15), 200);
map.put(new Employee("Lisa", 20), 400);
map.forEach((k,v) -> System.out.println(k + ":" + v));
}
}
Exception in thread "main" java.lang.ClassCastException: class GrokkingInterview.Grokking.Question109.Program2.Employee cannot be cast to class java.lang.Comparable (GrokkingInterview.Grokking.Question109.Program2.Employee is in unnamed module of loader 'app'; java.lang.Comparable is in module java.base of loader 'bootstrap')
at java.base/java.util.TreeMap.compare(TreeMap.java:1563)
at java.base/java.util.TreeMap.addEntryToEmptyMap(TreeMap.java:768)
at java.base/java.util.TreeMap.put(TreeMap.java:777)
at java.base/java.util.TreeMap.put(TreeMap.java:534)
at GrokkingInterview.Grokking.Question109.Program2.TestTreeMap.main(TestTreeMap.java:19)
We get ClassCastException at runtime. Now, let’s implement Comparable interface in Employee class and provide implementation of its compareTo() method:
- Program 3: ```java
import java.util.TreeMap;
class Employee implements Comparable
public class TestTreeMap { public static void main(String[] args) {
TreeMap<Employee, Integer> map = new TreeMap<>();
map.put(new Employee("Mike", 20), 100);
map.put(new Employee("John", 10), 500);
map.put(new Employee("Ryan", 15), 200);
map.put(new Employee("Lisa", 20), 400);
map.forEach((k,v) -> System.out.println(k + ":" + v)); } } ``` Here, we are sorting based on `Employee` name,
Output:
Employee [name=John, age=10]:500
Employee [name=Lisa, age=20]:400
Employee [name=Mike, age=20]:100
Employee [name=Ryan, age=15]:200
Let’s look at a program where we pass a Comparator in the TreeMap constructor, and sort the Employee object’s based on age in descending order:
- Program 4:
import java.util.Comparator;
import java.util.TreeMap;
import java.util.TreeSet;
class Employee {
String name;
int age;
Employee(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Employee [name=" + name + ", age=" + age + "]";
}
}
public class TestTreeMap {
public static void main(String[] args) {
TreeMap<Employee, Integer> map = new TreeMap<>(
new Comparator<Employee>() {
@Override
public int compare(Employee e1, Employee e2) {
if(e1.age < e2.age){
return 1;
} else if(e1.age > e2.age) {
return -1;
}
return 0;
}
}
);
map.put(new Employee("Mike", 20), 100);
map.put(new Employee("John", 10), 500);
map.put(new Employee("Ryan", 15), 200);
map.put(new Employee("Lisa", 40), 400);
map.forEach((k,v) -> System.out.println(k + ":" + v));
}
}
Output:
Employee [name=Lisa, age=40]:400
Employee [name=Mike, age=20]:100
Employee [name=Ryan, age=15]:200
Employee [name=John, age=10]:500
Here, in Employee class, I have not implemented equals() and hashCode()
TreeMap’s Javadoc:
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
{
/**
* The comparator used to maintain order in this tree map, or
* null if it uses the natural ordering of its keys.
*
* @serial
*/
private final Comparator<? super K> comparator ;
private transient Entry<K,V> root ;
//No-arg TreeMap constructor:
public TreeMap() {
comparator = null ;
}
}
TreeMap constructor which takes comparator object:
public TreeMap(Comparator<? super K> comparator ) {
this .comparator = comparator ;
}
// TreeMap.put() method excerpt:
public V put(K key , V value ) {
Entry<K,V> t = root ;
if (t == null ) {
compare(key , key ); // type (and possibly null) check
root = new Entry<>(key , value , null );
size = 1;
modCount ++;
return null ;
}
int cmp ;
Entry<K,V> parent ;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator ;
if (cpr != null ) {
do {
parent = t ;
cmp = cpr .compare(key , t .key );
if (cmp < 0)
t = t .left ;
else if (cmp > 0)
t = t .right ;
else
return t .setValue(value );
} while (t != null );
}
TreeSet
TreeSet class is one of the implementation of Set interface
Some points to remember:
- TreeSet class contains unique elements just like HashSet
- TreeSet class does not allow null elements
- TreeSet class is not synchronized
- TreeSet class internally uses TreeMap, i.e. the value added in TreeSet is internally stored in the key of TreeMap
- TreeSet elements are ordered using their natural ordering or by a Comparator which can be provided at the set creation time
- TreeSet provides guaranteed log(n) time cost for the basic operations (add, remove and contains)
- TreeSet iterator is fail-fast in nature
TreeSet Javadoc:
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
public TreeSet() {
this (new TreeMap<E,Object>());
}
public TreeSet(Comparator<? super E> comparator ) {
this (new TreeMap<>(comparator ));
}
fail-safe and fail-fast iterators
Iterators in Java are used to iterate over the Collection objects.
Fail-fast iterators
immediately throw ConcurrentModificationException, if the collection is modified while iterating over it. Iterator of ArrayList and HashMap are fail-fast iterators. All the collections internally maintain some sort of array to store the elements, Fail-fast iterators fetch the elements from this array. Whenever, we modify the collection, an internal field called modCount is updated. This modCount is used by Fail-safe iterators to know whether the collection is structurally modified or not. Every time when the Iterator’s next() method is called, it checks the modCount. If it finds that modCount has been
updated after the Iterator has been created, it throws ConcurrentModificationException.
Program 1:
import java.util.ArrayList;
import java.util.Iterator;
public class FailFastIteratorTest {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator<Integer> itr = list.iterator();
while(itr.hasNext()) {
System.out.println(itr.next());
list.add(4);
}
}
}
Output:
1
Exception in thread "main" java.util.ConcurrentModificationException
at java.base/java.util.ArrayList$Itr.checkForComodification(ArrayList.java:1013)
at java.base/java.util.ArrayList$Itr.next(ArrayList.java:967)
at GrokkingInterview.Grokking.Question111.Failfastiterator.Program1.FailFastIteratorTest.main(FailFastIteratorTest.java:16)
But they don’t throw the exception, if the collection is modified by Iterator’s remove() method.
Program 2:
import java.util.ArrayList;
import java.util.Iterator;
public class FailFastIteratorTest {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
System.out.println("List: " + list);
Iterator<Integer> itr = list.iterator();
while(itr.hasNext()) {
System.out.println(itr.next());
itr.remove();
}
System.out.println("List: " + list);
}
}
Output:
List: [1, 2, 3]
1
2
3
List: []
Javadoc:
arrayList.iterator() method:
public Iterator<E> iterator(){
return new Itr();
}
Itr is a private nested class in ArrayList:
private class Itr implements Iterator<E> {
int cursor ; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount ;
Itr() {}
public boolean hasNext() {
return cursor != size ;
}
Itr.next() method:
@SuppressWarnings ("unchecked" )
public E next() {
checkForComodification();
int i = cursor ;
if (i >= size )
throw new NoSuchElementException();
Object[] elementData = ArrayList.this .elementData ;
if (i >= elementData .length )
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData [lastRet = i ];
}
See the first statement is a call to checkForComodification():
final void checkForComodification() {
if (modCount != expectedModCount )
throw new ConcurrentModificationException();
}
On the other hand,
Fail-safe iterators
does not throw ConcurrentModificationException , because they operate on the clone of the collection, not the actual collection. This also means that any modification done on the actual collection goes unnoticed by these iterators. The last statement is not always true though, sometimes it can happen that the iterator may reflect modifications to the collection after the iterator is created. But there is no guarantee of it. CopyOnWriteArrayList, ConcurrentHashMap are the examples of fail-safe iterators.
Program 1: ConcurrentHashMap example
import java.util.Iterator;
import java.util.TreeMap;
import java.util.concurrent.CopyOnWriteArrayList;
public class FailSafeIteratorTest {
public static void main(String[] args) {
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator<Integer> itr = list.iterator();
while(itr.hasNext()) {
System.out.println(itr.next());
list.add(4);
}
System.out.println("List: " + list);
}
}
Output:
1 : Mike
2 : John
3 : Lisa
4 : Ryan
Map: {1=Mike, 2=John, 3=Lisa, 4=Ryan}
Here, iterator is reflecting the element which was added during the iteration operation.
Program 2: CopyOnWriteArrayList example
import java.util.Iterator;
import java.util.TreeMap;
import java.util.concurrent.CopyOnWriteArrayList;
public class FailSafeIteratorTest {
public static void main(String[] args) {
CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>();
list.add(1);
list.add(2);
list.add(3);
Iterator<Integer> itr = list.iterator();
while(itr.hasNext()) {
System.out.println(itr.next());
list.add(4);
}
System.out.println("List: " + list);
}
}
Output:
1
2
3
List: [1, 2, 3, 4, 4, 4]