Microservices
Table of contents
- SOA(Service-oriented architecture) vs Microservices
- Advantages and Disadvantages
- Gateway
- Microservices Monitor
- How does Microservice Architecture work?
- Communicating Between Microservices
- SOAP vs REST
- Eureka Naming Server
- Versioning of microservices
- How to send custom business errors or exceptions from a RESTful microservice to client application?
- What are best practices for microservices architecture?
- Microservices caching
- SOLID (solid design principles)
- How frequent a microservice be released into production?
- How to achieve zero-downtime during the deployments?
- Blue-green deployment
- How to slowly move users from older version of application to newer version?
- How will you monitor fleet of microservices in production?
- How will you troubleshoot a failed API request that is spread across multiple services?
- What are different layers of a single microservice?
- application.yml vs bootstrap.yml
- Netflix Eureka Server
- Netflix Eureka Server:
- Consul Server
- How does Eureka Server work?
- Externalize configuration in a distributed system
- Refresh configuration changes on the fly in Spring Cloud environment
- Achieve client side load balancing in Spring Microservices using Spring Cloud
- Client side load-balancer Ribbon in your microservices architecture
- Use both LoadBalanced as well as normal RestTemplate object in the single microservice
- Use of Eureka for service discovery in Ribbon Load Balancer
Microservices - also known as the microservice architecture - is an architectural style that structures an application as a collection of services that are
- Highly maintainable and testable
- Loosely coupled
- Independently deployable
- Organized around business capabilities
- Owned by a small team
The microservice architecture enables the rapid, frequent and reliable delivery of large, complex applications. It also enables an organization to evolve its technology stack.
What is Micro Service?
Micro Service is an architecture that allows the developers to develop and deploy services independently. Each service running has its own process and this achieves the lightweight model to support business applications.
SOA(Service-oriented architecture) vs Microservices
| SOA | Microservices |
|---|---|
| SOA model has a single data storage layer which shared by all of the services in that application. | Microservices apps mostly dedicate a database or other type of storage to services that need it. |
| Focused on maximizes application service reusability. | More focused on decoupling. |
| Involves sharing data storage between services | Each service can have independent data storage. |
| Better for large scale integrations | Better for small and web-based applications. |
| Less flexibility in deployment | Quick and easy deployment. |
| Uses enterprise service bus (ESB) for communication | Communicates through an API layer |
| Less scalable architecture. | Highly scalable architecture. |
Advantages and Disadvantages
In monolithic architecture, applications are built as one large system, whereas in micro-service architecture we divide the application into modular components which are independent of each other.
Advantages of Monolithic architecture
- Development is quite simple
- Testing a monolith is also simple, just start the application and do the end-to-end testing, Selenium can be used to do the automation testing
- These applications are easier to deploy, as only one single jar/war needs to be deployed
- Scaling is simple when the application size is small, we just have to deploy one more instance of our monolith and distribute the traffic using a load balancer
- Network latency is very low/none because of one single codebase
Disadvantages of monolith architecture
- Rolling out a new version means redeploying the entire application
- Scaling a monolith application becomes difficult once the application size increases. It also becomes difficult to manage
- The size of the monolith can slow down the application start-up and deployment time
- Continuous deployment becomes difficult
- A bug in any module can bring down the entire application
- It is very difficult to adopt any new technology in a monolith application, as it affects the whole application, both in terms of time and cost
Advantages of Micro-service architecture
- Micro-services are easier to manage as they are relatively smaller in size
- Scalability is a major advantage of using a micro-service architecture, each micro-service can be scaled independently
- Rolling out a new version of micro-service means redeploying only that micro-service
- A bug in micro-service will affect only that micro-service and its consumers, not the entire application
- Micro-service architecture is quite flexible. We can choose different technologies for different micro-services according to business requirements
- It is not that difficult to upgrade to newer technology versions or adopt a newer technology as the codebase is quite smaller (this point is debatable in case the micro-service becomes very large)
- Continuous deployment becomes easier as we only have to re-deploy that micro-service.
Disadvantages of Micro-services architecture
- As micro-services are distributed, it becomes complex compared to monolith. And this complexity increases with the increase in micro-services
- As micro-services will need to communicate with each other, it increases the network latency. Also, extra efforts are needed for a secure communication between micro-services
- Debugging becomes very difficult as one micro-service will be calling other micro-services and to figure out which micro-service is causing the error, becomes a difficult task in itself
- Deploying a micro-service application is also a complex task, as each service will have multiple instances and each instance will need to be configured, deployed, scaled and monitored
- Breaking down a large application into individual components as micro-services is also a difficult task
We have discussed both advantages and disadvantages of monolith and micro-services, you can easily figure out the differences between them, however, I am also stating them below.
The differences
- In a monolithic architecture, if any fault occurs, it might bring down the entire application as everything is tightly coupled, however, in case of micro-service architecture, a fault affects only that micro-service and its consumers
- Each micro-service can be scaled independently according to requirement. For example, if you see that one of your micro-service is taking more traffic, then you can deploy another instance of that micro-service and then distribute the traffic between them. Now, with the help of cloud computing services such as AWS, the applications can be scaled up and down automatically. However, in case of monolith, even if we want to scale one service within the monolith, we will have to scale the entire monolith
- In case of monolith, the entire technology stack is fixed at the start. It will be very difficult to change the technology at a later stage in time. However, as micro-services are independent of each other, they can be coded in any language, taking the advantage of different technologies according to the use-case. So micro-services gives you the freedom to choose different technologies, frameworks etc.
- Deploying a new version of a service in monolith requires more time and it increases the application downtime, however, micro-services entails comparatively lesser downtime
| Advantage | Description |
|---|---|
| Independent Development | All microservices can be easily developed based on their individual functionality |
| Independent Deployment | Based on their services, they can be individually deployed in any application |
| Fault Isolation | Even if one service of the application does not work, the system still continues to function |
| Mixed Technology Stack | Different languages and technologies can be used to build different services of the same application |
| Granular Scaling | Individual components can scale as per need, there is no need to scale all components together |
- Microservices are self-contained, independent deployment module.
- The cost of scaling is comparatively less than the monolithic architecture.
- Microservices are independently manageable services. It can enable more and more services as the need arises. It minimizes the impact on existing service.
- It is possible to change or upgrade each service individually rather than upgrading in the entire application.
- Microservices allows us to develop an application which is organic (an application which latterly upgrades by adding more functions or modules) in nature.
- It enables event streaming technology to enable easy integration in comparison to heavyweight interposes communication.
- Microservices follows the single responsibility principle.
- The demanding service can be deployed on multiple servers to enhance performance.
- Less dependency and easy to test.
- Dynamic scaling.
- Faster release cycle.
Microservices vs Monolithic Architecture
-
Microservices
- Service Startup is fast
- Microservices are loosely coupled architecture.
- Changes done in a single data model does not affect other Microservices.
- Microservices focuses on products, not projects
-
Monolithic Architecture
- Service startup takes time
- Monolithic architecture is mostly tightly coupled.
- Any changes in the data model affect the entire database
- Monolithic put emphasize over the whole project
Disadvantages of Microservices
- Microservices has all the associated complexities of the distributed system.
- There is a higher chance of failure during communication between different services.
- Difficult to manage a large number of services.
- The developer needs to solve the problem, such as network latency and load balancing.
- Complex testing over a distributed environment.
Challenges of Microservices Architecture
- Bounded context: The bounded context concept originated in Domain-Driven Design (DDD) circles. It promotes the Object model first approach to service, defining a data model that service is responsible for and is bound to. A bounded context clarifies, encapsulates, and defines the specific responsibility to the model. It ensures that the domain will not be distracted from the outside. Each model must have a context implicitly defined within a sub-domain, and every context defines boundaries. In other words, the service owns its data and is responsible for its integrity and mutability. It supports the most important feature of microservices, which is independence and decoupling.
- Dynamic scale up and scale down: The loads on the different microservices may be at a different instance of the type. As well as auto-scaling up your microservice should auto-scale down. It reduces the cost of the microservices. We can distribute the load dynamically.
- Monitoring: The traditional way of monitoring will not align well with microservices because we have multiple services making up the same functionality previously supported by a single application. When an error arises in the application, finding the root cause can be challenging.
- Fault Tolerance: Fault tolerance is the individual service that does not bring down the overall system. The application can operate at a certain degree of satisfaction when the failure occurs. Without fault tolerance, a single failure in the system may cause a total breakdown. The circuit breaker can achieve fault tolerance. The circuit breaker is a pattern that wraps the request to external service and detects when they are faulty. Microservices need to tolerate both internal and external failure.
- Cyclic Dependency: Dependency management across different services, and its functionality is very important. The cyclic dependency can create a problem, if not identified and resolved promptly.
- DevOps Culture: Microservices fits perfectly into the DevOps. It provides faster delivery service, visibility across data, and cost-effective data. It can extend their use of containerization switch from Service-Oriented-Architecture (SOA) to Microservice Architecture (MSA).
- The traditional logging is ineffective because microservices are stateless, distributed, and independent. The logging must be able to correlate events across several platforms.
- When more services interact with each other, the possibility of failure also increases.
Gateway
Clients will not directly invoke microservices, they will go through the Gateway. The Gateway in turn can call the microservices and will return the response to the client. The Gateway can decouple the microservices from the clients. It will provide functions such as authentication, logging, load balancing etc.
Microservices Monitor
Spring Boot actuator will be a good tool monitor metrics, counters for individual microservices. But if we have multiple microservices, it is difficult to monitor each individually. We will use open source tools such as Prometheous, Kibana or Graphana for this . Prometheous is a pull based monitoring tool and it will contain metrics at provided intervals, displays them and will also trigger alerts. Kibana or Grafana are dashboard tools which are used for visualizing and monitor the data. When there will be large number of microservices with dependencies, we will use AppDynamics, Dynatrace, and New Relic that will draw dependencies among microservices.
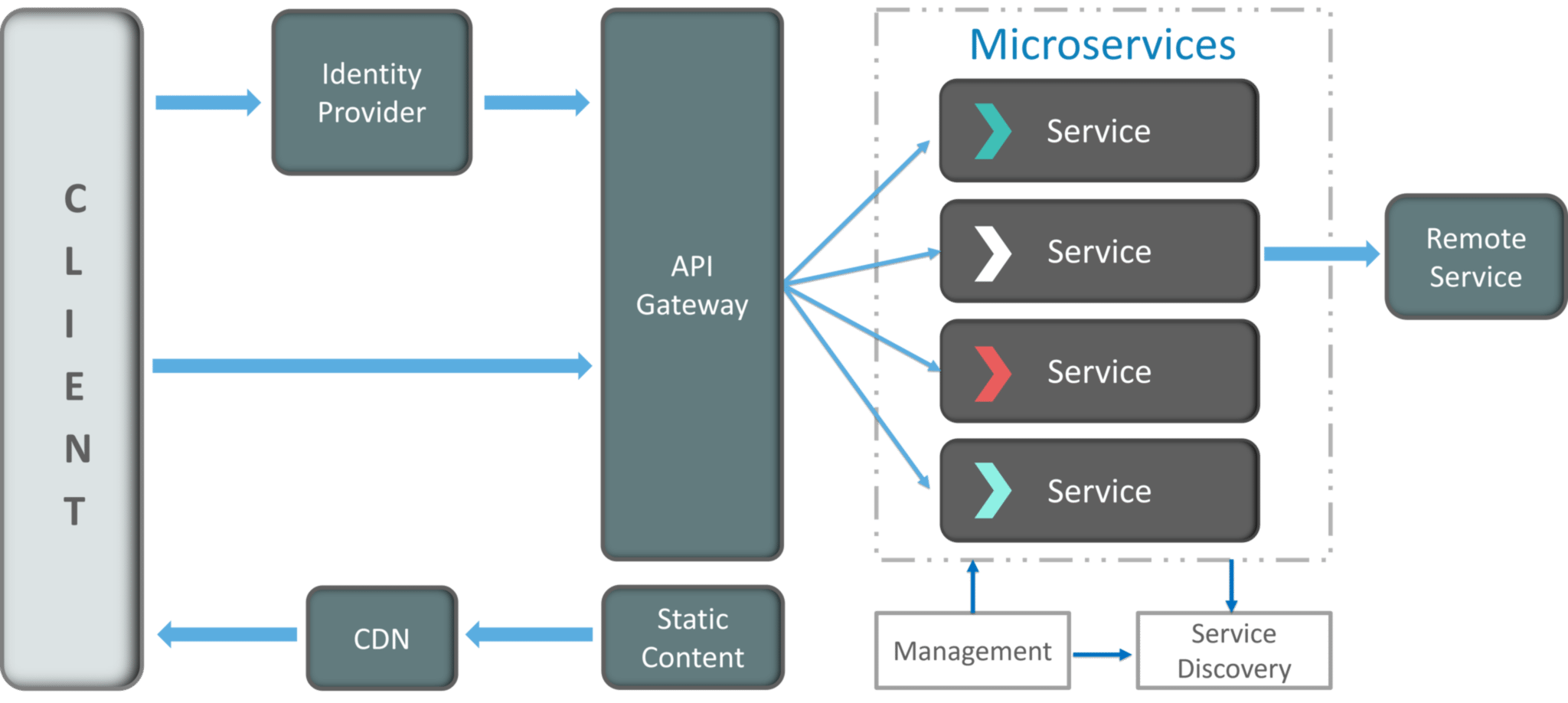
How does Microservice Architecture work?
A microservice architecture has the components:
- Clients – Different users from various devices send requests.
- Identity Providers – Authenticates user or clients identities and issues security tokens.
- API Gateway – Handles client requests.
- Static Content – Houses all the content of the system.
- Management – Balances services on nodes and identifies failures.
- Service Discovery – A guide to find the route of communication between microservices.
- Content Delivery Networks – Distributed network of proxy servers and their data centers.
- Remote Service – Enables the remote access information that resides on a network of IT devices.
Communicating Between Microservices
Inter-service communication in Microservices:
Synchronous Communication
This type of communication happens in real-time and requires a response from the service before the calling service can continue its execution. This is usually achieved through REST or gRPC API calls, where the calling service sends a request to the other service and waits for a response.
Asynchronous Communication
This type of communication does not require a real-time response and allows for decoupling between services. This is usually achieved through messaging systems like Kafka, RabbitMQ, and ActiveMQ. Services can send and receive messages asynchronously without waiting for a response.
Shared Data Storage
Some microservices may share data storage and communicate with each other through the data store. This can be achieved by using a shared database or a shared cache like Redis.
Event-Driven Communication
This type of communication allows services to communicate with each other by publishing and subscribing to events. Services can publish events to a message broker and other services can subscribe to those events.
API Gateway
An API Gateway is a reverse proxy that acts as a single entry point for all the microservices. It can handle routing, security, and rate limiting for the services. It can also aggregate data from different services and return it as a single response to the client.
It’s important to note that the best approach for microservices communication will depend on the specific requirements of the application, and it’s also possible to use a combination of these techniques.
SOAP vs REST
The differences are:
- SOAP stands for Simple Object Access Protocol and REST stands for Representational State Transfer
- SOAP is a protocol whereas REST is an architectural style
- SOAP cannot use REST because it is a protocol whereas REST can use SOAP web services as the underlying protocol, because it is just an architectural pattern
- SOAP uses service interfaces to expose its functionality to client applications whereas REST uses URI to expose its functionality
- SOAP defines standards that needs to be strictly followed for communication to happen between client and server whereas REST does not follow any strict standard
- SOAP requires more bandwidth and resources than REST because SOAP messages contain a lot of information whereas REST requires less bandwidth than SOAP because REST messages mostly just contains a simple JSON message
- SOAP only works with XML format whereas REST allows different data formats like Plain text, HTML, XML, JSON etc.
- SOAP defines its own security whereas REST inherits the security
Eureka Naming Server
let’s consider an example. Suppose you have 5 micro-services which are experiencing heavy traffic and you want to deploy multiple instances of these 5 micro-services and use a load balancer to distribute the traffic among these instances. Now, when you create new instances of your micro-service, you have to configure these in your load balancer, so that load balancer can distribute traffic properly. Now, when your network traffic will reduce then you will most likely want to remove some instances of your micro-service, means you will have to remove the configuration from your load balancer. I think, you see the problem here.
This manual work that you are doing can be avoided by using Eureka naming server. Whenever a new service instance is being created/deleted, it will first register/de-register itself to the Eureka naming server. Then you can simply configure a Ribbon client (Load Balancer) which will talk with Eureka Naming server to know about the currently running instances of your service and Ribbon will properly distribute the load between them. Also, if one service, serviceA wants to talk with another service, serviceB then also Eureka Naming server will be used to know about the currently running instances of serviceB. You can configure Eureka Naming Server and Ribbon client in SpringBoot very easily.
Zuul
Zuul is an API gateway server. It handles all the requests that are coming to your application. As it handles all the requests, you can implement some common functionalities of your micro-services as part of Zuul server like Security, Monitoring etc. You can monitor the incoming traffic to gain some insights and also provide authentication at a single place rather than repeating it in your services. Using Zuul, you can dynamically route the incoming requests to the respective micro-services. So, the client doesn’t have to know about the internal architecture of all the services, it will only call the Zuul server and Zuul will internally route the request.
Zipkin
To understand Zipkin use-case, let’s consider an example. Suppose you have a chain of 50 micro-services where first micro-service is calling the second and second calling third and so on. Now, if there is an error in, say 35th micro-service, then how you will be able to identify your request that you made to the first micro-service, from all the logs that gets generated in all 35 micro-services. I know this is an extreme example
Zipkin helps in distributed tracing, especially in a micro-service architecture. It assigns an ‘id’ to each request and gives you a dashboard, where you can see the complete request and a lot more details, like the entire call-chain, how much time one micro-service took and which service failed etc.
Hystrix
Hystrix is a library that makes our micro-service, fault-tolerant. Suppose, you have a chain of 10 micro-services calling each other and the 6th one fails for some reason, then your application will stop working until the failed micro-service is fixed.
You can use Hystrix here and provide a fallback method in case of a service failure.
@GetMappinng("/getByName/{name}")
@HystrixCommannd(fallbackMethod = "handlerMethod")
public String. getMapping(@PathVariable String name){
return "Get";
}
public String handleMethod(){
return "Service is down";
}
If the GET service is getting failed, then the fallback method will be executed.
Versioning of microservices
There are different ways to handle the versioning of your REST api to allow older consumers still consume the older endpoints. The ideal practice is that any non backward compatible change in a given REST endpoint shall lead to a new versioned endpoint.
Different mechanisms of versioning are:
- Add version in the URL itself
- Add version in API request header Most common approach in versioning is the URL versioning itself. A versioned URL looks like the following:
Versioned URL
https://<host>:<port>/api/v1/... https://<host>:<port>/api/v2/...
As a API developer we must ensure that only backward compatible changes are accommodated in a single version of URL. Consumer-Driven-Tests can help identify potential issues with API upgrades at an early stage.
How to send custom business errors or exceptions from a RESTful microservice to client application?
In RESTful applications, often is not enough to just send the HTTP error codes for representing the business errors. HTTP error codes can tell about the kind of failure but will not be able to point to business error codes. The solution to this is to wrap our service response inside a custom object that can reveal more information about the failure reason, error codes for machine and developers.
The below class is an example showing how we can wrap additional information about the business exception such as errorCode, userMessage, developerMessage, etc. inside a service response.
Typical Implementation of ServiceResponse Wrapper Class.
public class ServiceResponse<T> {
T data;
boolean success;
int errorCode;
String moreInfo;
String userMessage;
String developerMessage;
List<String> errors = new ArrayList<>();
//Getter and setters removed for brevity
}
Now in our Rest Controller, we can create an instance of this ServiceResponse and send it back to the RestClient.
Rest Controller that Fetches Order Information.
ServiceResponse<Order> response = new ServiceResponse<>();
Order order = //Get Order from remote microservices
if(order!=null) {
response.setData(order);
response.setSuccess(true);
} else {
response.setErrorCode(12254);
response.setSuccess(false);
}
return response;
12254 here is the business error code that api client would know how to deal with.
What are best practices for microservices architecture?
Microservices Architecture can become cumbersome & unmanageable if not done properly. There are best practices that help design a resilient & highly scalable system. The most important ones are -
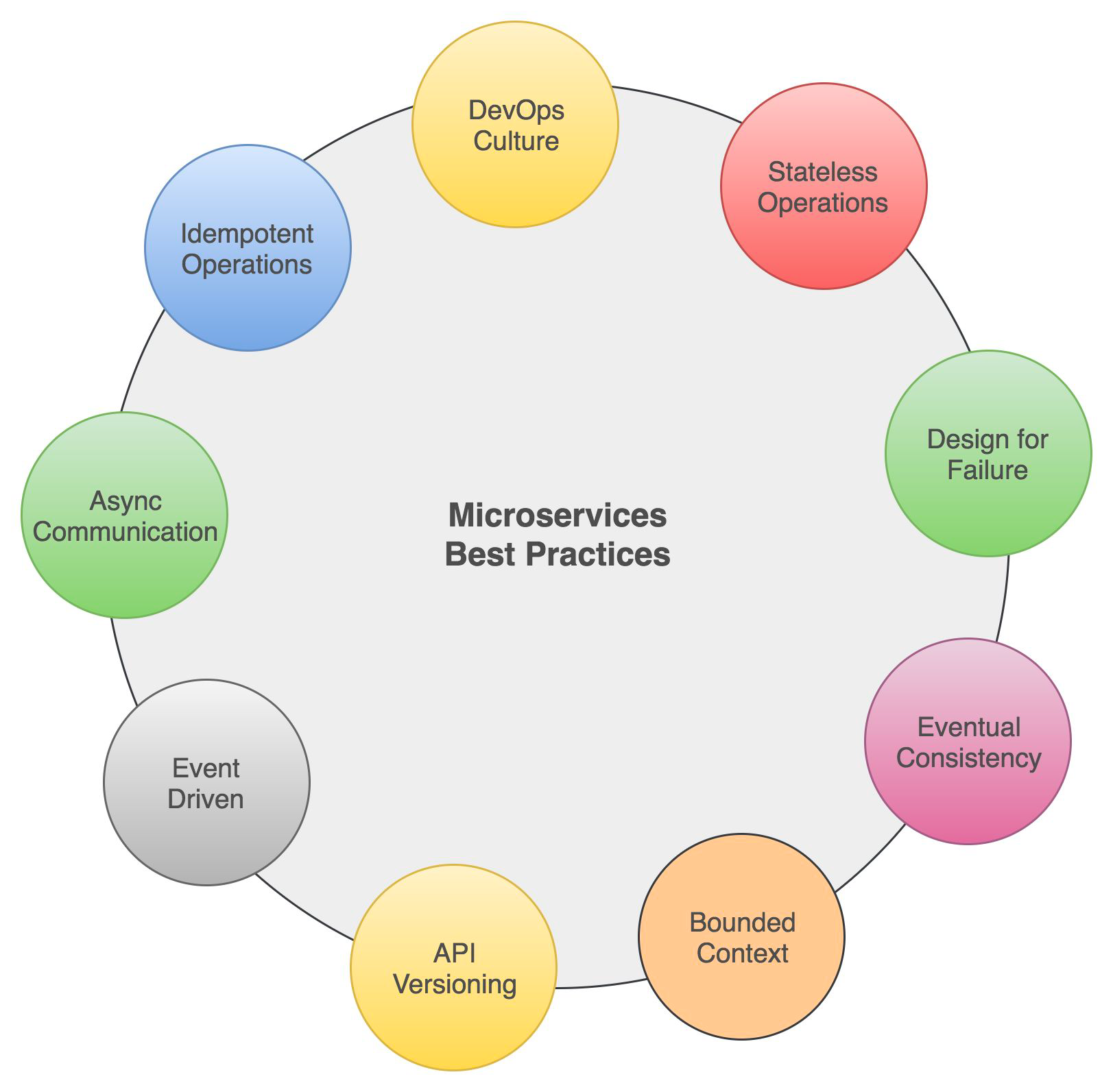
Partition correctly
Get to know the domain of your business, thats very very important. Only then you will be able to define the bounded context and partition your microservice correctly based on business capabilities.
DevOps culture
Typically, everything from continuous integration all the way to continuous delivery and deployment should be automated. Otherwise its a big pain to manage large fleet of microservices.
Design for stateless operations
We never know where a new instance of a particular microservice will be spun up for scaling out or for handling a failure, so maintaining a state inside service instance is a very bad idea.
Design for failures
Failures are inevitable in distributed systems, so we must design our system for handling failures gracefully. failures can be of different types and must be dealt accordingly,
for example -
- Failure could be transient due to inherent brittle nature of the network, and the next retry may succeed. Such failures must be protected using retry operations.
- Failure may be due to a hung service which can have cascading effects on the calling service. Such failures must be protected using Circuit Breaker Patterns. A fallback mechanism can be used to provide degraded functionality in this case.
- A single component may fail and affect the health of entire system, bulkhead pattern must be used to prevent entire system from failing.
Design for versioning
We should try to make our services backward compatible, explicit versioning must be used to cater different versions of the RESt endpoints. Design for asynchronous communication b/w services Asynchronous communication should be preferred over synchronous communication in inter microservice communication. One of the biggest advantages of using asynchronous messaging is that the service does not block while waiting for a response from another service.
Design for eventual consistency
Eventual consistency is a consistency model used in distributed computing to achieve high availability that informally guarantees that, if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value.
Design for idempotent operations
Since networks are brittle, we should always design our services to accept repeated calls without any side effects. We can add some unique identifier to each request so that service can ignore the duplicate request sent over the network due to network failure/retry logic.
Share as little as possible
In monolithic applications sharing is considered to be a best practice but thats not the case with Microservices. Sharing results in violation of Bounded Context Principle, so we shall refrain from creating any single unified shared model that works across microservices. For example, if different services need a common Customer model, then we should create one for each microservice with just the required fields for a given bounded context rather than creating a big model class that is shared in all services. The more dependencies we have between services, the harder it is to isolate the service changes, making it difficult to make change in a single service without effecting other service. Also, creating a unified model that works in all services brings complexity and ambiguity to the model itself, making it hard for anyone to understand the model.
In a way are want to violate the DRY principle in microservices architecture when it comes to domain models.
Reference: https://blogs.oracle.com/developers/getting-started-with-microservices-part-three
Microservices caching
Caching is a technique of performance improvement for getting query results from a service. It helps minimize the calls to network, database, etc. We can use caching at multiple levels in microservices architecture -
- Server Side Caching - Distributed caching softwares like Redis/MemCache/etc are used to cache the results of business operations. The cache is distributed so all instances of a microservice can see the values from shared cache. This type of caching is opaque to clients.
- Gateway Cache - central API gateway can cache the query results as per business needs and provide an improved performance. This way we can achieve caching for multiple services at one place. Distributed caching software like Redis or Memcache can be used in this case.
- Client Side Caching - We can set cache-headers in http response and allow clients to cache the results for pre-defined time. This will drastically reduce load on servers since client will not make repeated calls to same resource. Servers can inform the clients when information is changed, thereby any changes in the query result can also be handled. E-Tags can be used for client side load balancing. If the end client is a microservice itself, then Spring Cache support can be used to cache the results locally.
SOLID (solid design principles)
SOLID is a mnemonic acronym for five design principles intended to make software designs more understandable, flexible and maintainable. The five design principles are,
- Single responsibility principle - a class should have only a single responsibility (i.e. changes to only one part of the software’s specification should be able to affect the specification of the class).
- Open/Close Principle - “software entities … should be open for extension, but closed for modification.”
- Liskov substitution principle - “objects in a program should be replaceable with instances of their subtypes without altering the correctness of that program.”
- Interface segregation principle - “many client-specific interfaces are better than one general-purpose interface.”
- Dependency inversion principle - one should “depend upon abstractions, [not] concretions.”
The principles are a subset of many principles promoted by Robert C. Martin.
Reference: https://medium.zenika.com/solid-microservices-design-dc6a4044a050
How frequent a microservice be released into production?
There is no definitive answer to this question, there could be a release every ten minutes, every hour or once a week. It all depends on the extent of automation you have at different level of software development lifecycle - build automation, test automation, deployment automation and monitoring. And of course on the business requirements - how small lowrisk changes you care making in a single release.
In an ideal world where boundaries of each microservices are clearly defined (bounded context), and a given service is not affecting other microservices, you can easily achieve multiple deployments a day without major complexity.
Examples of deployment/release frequency
- Amazon is on record as making changes to production every 11.6 seconds on average in May of 2011. https://www.thoughtworks.com/insights/blog/case-continuous-delivery
- Github is well known for its aggressive engineering practices, deploying code into production on an average 60 times a day. https://githubengineering.com/move-fast/
- Facebook releases to production twice a day.
- Many Google services see releases multiple times a week, and almost everything in Google is developed on mainline.
- Etsy Deploys More Than 50 Times a Day. https://www.infoq.com/news/2014/03/etsy-deploy-50-times-a-day
- Each microservices must be autonomous with least possible dependency on other services. Principles like Bounded-Context, Single Responsibility Principle, async communication using messages can help here.
- Good level of automation at all levels of software development, so that a single commit in git repository can trigger the build, run automated testcases, deploy builds automatically.
- Each change must contain small set of low-risk business requirements.
How to achieve zero-downtime during the deployments?
As the name suggests, zero-downtime deployments do not bring outage in production environment. It is a clever way of deploying your changes to production where at any given point in time, atleast one service will remain available to customers.
Blue-green deployment
One way of achieving this is blue/green deployment. In this approach, two versions of a single microservice are deployed at a time. But only one version is taking real requests. Once the newer version is tested to the required satisfaction level, you can switch from older version to newer version.
You can run a smoke-test suite to verify that the functionality is running correctly in the newly deployed version. Based on the results of smoke-test, newer version can be released to become the live version.
Changes required in client code to handle zero-downtime
Lets say you have two instances of a service running at same time, and both are registered in Eureka registry. Further, both the instances are deployed using two distinct hostnames:
/src/main/resources/application.yml.
spring.application.name: books-service
---
spring.profiles: blue
eureka.instance.hostname: books-service-blue.example.com
---
spring.profiles: green
eureka.instance.hostname: books-service-green.example.com
Now the client app that needs to make api calls to books-service may look like below:
/sample/ClientApp.java.
@RestController
@SpringBootApplication
@EnableDiscoveryClient
public class ClientApp {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
@RequestMapping("/hit-some-api")
public Object hitSomeApi() {
return restTemplate().getForObject("https://books-service/some-uri", Object.class);
}
We are calling the books-service using LoadBalanced RestTemplate.Now, when books-service-green.example.com goes down for upgrade, it gracefully shuts down and delete its entry from Eureka registry. But these changes will not be reflected in the
ClientApp until it fetches the registry again (which happens every 30 seconds). So for upto 30 seconds, ClientApp’s @LoadBalanced RestTemplate may send the requests to books-servicegreen. example.com even if its down.
To fix this, we can use Spring Retry support in Ribbon client-side load balancer. To enable Spring Retry, we need to follow the below steps:
Add spring-retry to build.gradle dependencies.
compile("org.springframework.boot:spring-boot-starter-aop")
compile("org.springframework.retry:spring-retry")
Now enable spring-retry mechanism in ClientApp using @EnableRetry annotation, as shown below:
@EnableRetry
@RestController
@SpringBootApplication
@EnableDiscoveryClient
public class ClientApp {
...
}
Once this is done, Ribbon will automatically configure itself to use retry logic and any failed request to books-service-green.example.com will be retried to next available instance (in roundrobins fashion) by Ribbon. You can customize this behavior using the below properties:
/src/main/resources/application.yml.
ribbon:
MaxAutoRetries: 5
MaxAutoRetriesNextServer: 5
OkToRetryOnAllOperations: true
OkToRetryOnAllErrors: true
Note If you have a single host machine and want to enable blue-green deployment strategy, then you need to start microservice at a dynamically available random port (in a predefined range). So two versions can work parallelly without causing port conflicts.
- https://github.com/spring-cloud/spring-cloud-netflix/issues/1290
- https://www.quora.com/What-is-the-role-played-by-Netflix-Eureka-in-blue-greendeployment-done-on-Pivotal-Cloud-Foundry
How to slowly move users from older version of application to newer version?
If you have two different versions of a single microservice, you can achieve slow migration by maintaining both version of the application in production and then using API gateway to forward only selected endpoints to newly developed microservice.
This technique is also known as Canary Releasing. In Canary Releasing two versions coexist for a much longer time period compared to blue/green deployment.
How will you monitor fleet of microservices in production?
Monitoring is an essential aspect when it comes to any production deployment. In Microservices Architecture, we have fleet of services deployed on different or same host machine, so it becomes absolutely necessary to keep track of health of each individual service and take proper action in case of a failure. There are various tools that can help us here -
- Graphite is an open source database that captures metrics from services in a time series database. By using Graphite we can capture essential metrics of multiple Microservices simultaneously. And we can use a dashboard like- Grafana to monitor these metrics in almost real time fashion. Graphite is built to handle large amount of data. It can record and show trends from few hours to few months within a few seconds. Many organizations like- Facebook etc use Graphite for monitoring. More information can be found herehttps://graphiteapp.org/
- Spring Boot Admin is an open source project provided by Spring Boot Team. Spring Boot provides a basic UI for monitoring Health of service, logs/hystrix stats, JVM & memory Metrics, Datasource Metrics, Thread dump etc. More information can be found here https://github.com/codecentric/spring-boot-admin
- Some of the other tools to monitor Microservices are:
AppDynamics,DynaTrace, etc. These are paid tools with some premium features.
How will you troubleshoot a failed API request that is spread across multiple services?
In distributed systems its really hard to find the place where service actually failed first. The cascading effects of failure will lead to error in upstream services. We can use Correlation IDs in microservices that are unique for each request and gets injected at the API gateway level. So if failure occurs, we can aggregate the logs for a single request and figure out the exact place where it failed first.
These are unique IDs like GUID that can be passed from one service to another service during an API call. By using a GUID and failure message associated with it we can find the source of failure as well as the impact of failure.
What are different layers of a single microservice?
Like any typical Java application, a microservice has layered architecture. Most common layers in any microservice are:
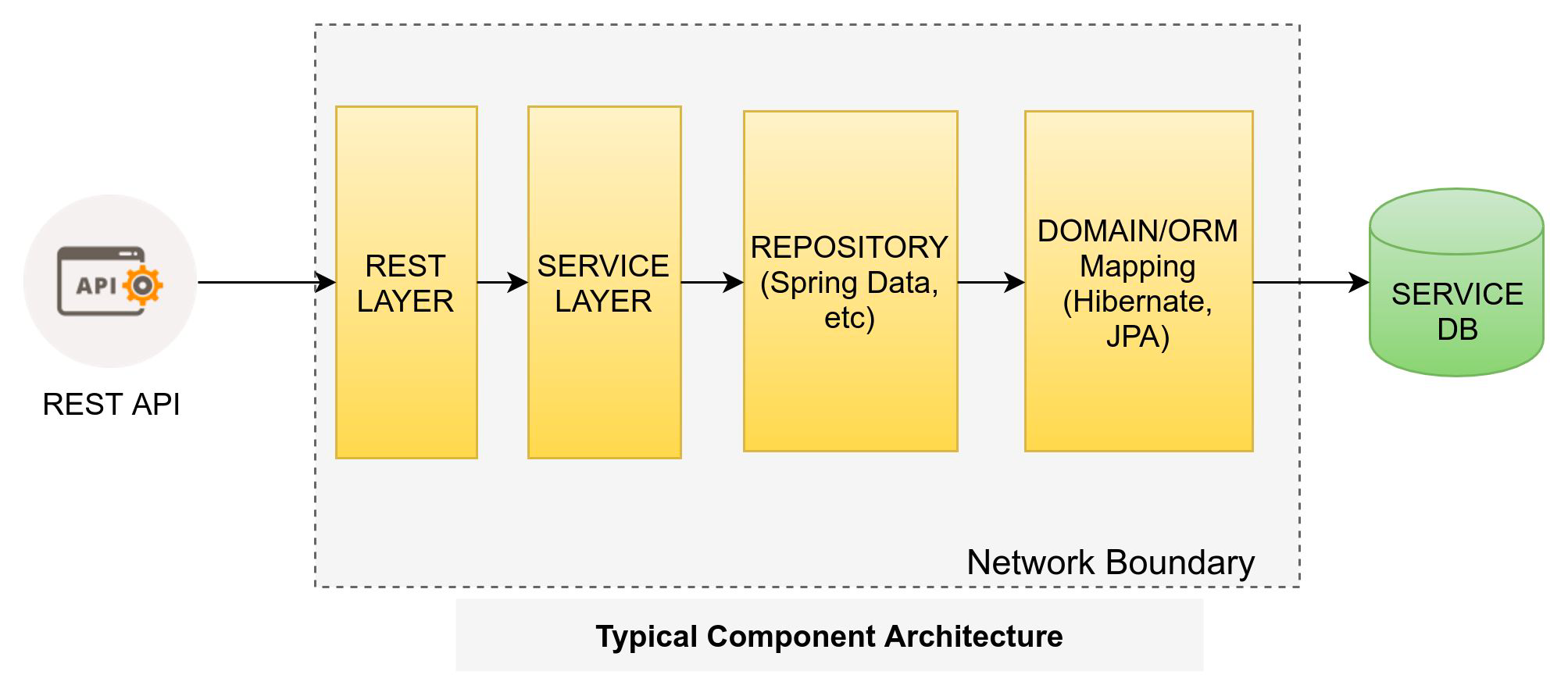
Note From layering perspective, any microservice is no different than any other 3-tier architecture application.
- Resource Layer (Rest Endpoint) - this layer is exposed to external world over HTTP.
- Service Layer - this layer contains the business logic
- Domain and Repository (Spring Data)
- ORM/Data Mapper (Hibernate, JPA) - contains mostly POJO that map a Java Object with database table(RDBMS) or collection(NoSql).
application.yml vs bootstrap.yml
application.yml
application.yml/application.properties file is specific to Spring Boot applications. Unless you change the location of external properties of an application, spring boot will always load application.yml from following location:
/src/main/resources/application.yml
You can store all the external properties for you application in this file. Common properties that are available in any Spring Boot project can be found at: https://docs.spring.io/springboot/docs/current/reference/html/common-application-properties.html You can customize these properties as per your application needs. Sample file is shown below:
/src/main/resources/application.yml.
spring:
application:
name: foobar
datasource:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost/test
server:
port: 9000
Reference. https://docs.spring.io/spring-boot/docs/current/reference/html/boot-features-externalconfig.html
bootstrap.yml
bootstrap.yml on the other hand is specific to spring-cloud-config and is loaded before the application.yml
bootstrap.yml is only needed if you are using Spring Cloud and your microservice configuration is stored on a remote Spring Cloud Config Server.
- When used with Spring Cloud Config server, you shall specify the application-name and config git location using below properties
/src/main/resources/bootstrap.yml.
spring.application.name: <application-name>
spring.cloud.config.server.git.uri: <git-uri-config>
- When used with microservices (other than cloud config server), we need to specify the application name and location of config server using below properties
/src/main/resources/bootstrap.yml.
spring.application.name: <application-name>
spring.cloud.config.uri: <http://localhost:8888>
- This properties file can contain other configuration relevant to Spring Cloud environment for e.g. eureka server location, encryption/decryption related properties.
Tip Upon startup, Spring Cloud makes an HTTP(S) call to the Spring Cloud Config Server with the name of the application and retrieves back that application’s configuration.
application.yml contains the default configuration for the microservice and any configuration retrieved (from cloud config server) during the bootstrap process will override configuration defined in application.yml
As per official Spring Cloud Documentation
A Spring Cloud application operates by creating a “bootstrap” context, which is a parent context for the main application. Out of the box it is responsible for loading configuration properties from the external sources, and also decrypting properties in the local external configuration files.
http://cloud.spring.io/spring-cloud-config/single/spring-cloud-config.html
Using YAML instead of Properties
YAML is a superset of JSON format and it is a very convenient format for specifying hierarchical configuration data. To support yaml based configuration in your Spring Boot project, you just need to add the following dependency:
build.gradle.
compile('org.springframework.boot:spring-boot-starter')
Tip It is recommended to use YAML format over conventional properties format because yaml is compact & easy to read.
Netflix Eureka Server
Implement service discovery in microservices architecture
Servers come and go in a cloud environment, and new instances of same services can be deployed to cater increasing load of requests. So it becomes absolutely essential to have service registry & discovery that can queried for finding address (host, port & protocol) of a given server. We may also need to locate servers for the purpose of client side load balancing (Ribbon) and handling failover gracefully (Hystrix).
Spring Cloud solves this problem by providing few ready made solutions for this challenge. There are mainly two options available for the service discovery - Netflix Eureka Server and Consul. Lets discuss both of these briefly:
Netflix Eureka Server:
Eureka is a REST (Representational State Transfer) based service that is primarily used in the AWS cloud for locating services for the purpose of load balancing and failover of middle-tier servers. The main features of of Netflix Eureka are:
- It provides service-registry.
- zone aware service lookup is possible.
- eureka-client (used by microservices) can cache the registry locally for faster lookup. The client also has a built-in load balancer that does basic round-robin load balancing.
In round-robin(akka RR) load-balancing, equal share of calls are distributed among various instances of single service in a circular fashion. Please note that this technique does not take into account priority or cpu/memory load, thus trivial to implement.
Spring Cloud provides two dependencies - eureka-server and eureka-client.
Eureka server dependency is only required in eureka server’s build.gradle
build.gradle - Eureka Server.
compile(‘org.springframework.cloud:spring-cloud-starter-netflix-eureka-server’)
On the other hand, each microservice need to include the eureka-client dependencies to enables eureka discovery.
build.gradle - Eureka Client (to be included in all microservices).
compile(‘org.springframework.cloud:spring-cloud-starter-netflix-eureka-client’)
Eureka server provides a basic dashboard for monitoring various instances and their health in service registry. The ui is written in freemarker and provided out of the box without any extra configuration. Screenshot for Eureka Server looks like the following.
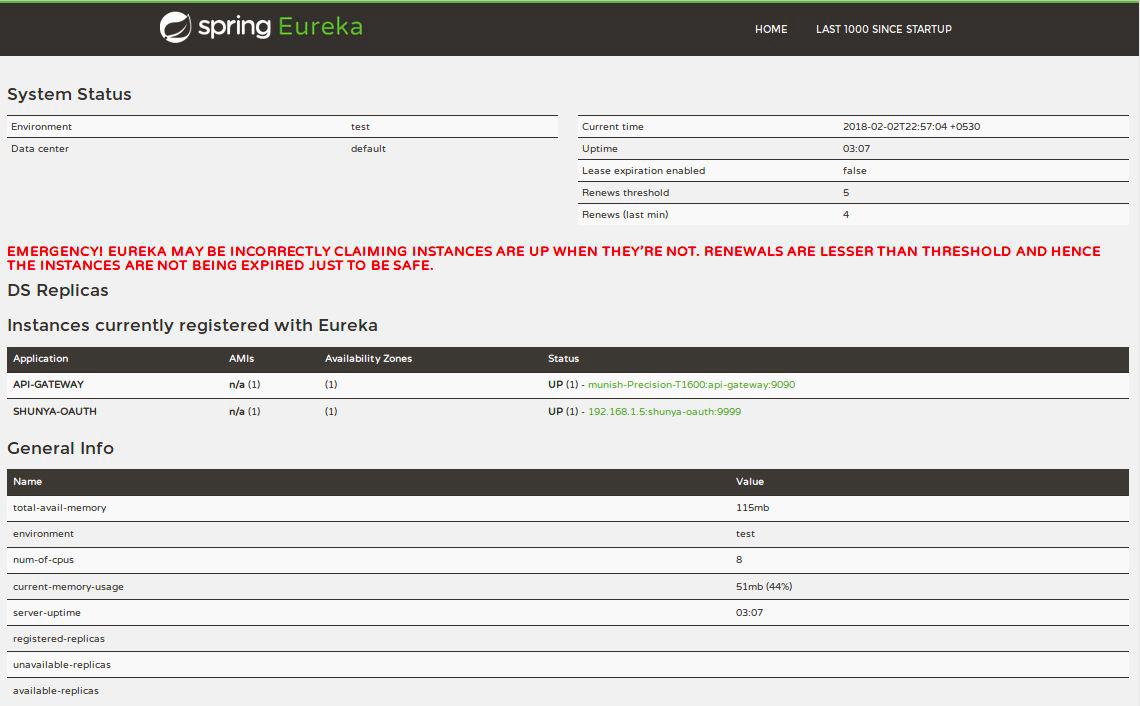
It contains list all services that are registered with Eureka Server. Each server has information like zone, host, port and protocol.
Consul Server
It is a REST based tool for dynamic service registry. It can be used for registering a new service, locating a service and health checkup of a service.
You have a option to choose any one of the above in your spring cloud based distributed application. In this book, we will focus more on the Netflix Eureka Server option.
How does Eureka Server work?
There are two main components in Eureka project: eureka-server and eureka-client.
Eureka Server The central server (one per zone) that acts as a service registry. All microservices register with this eureka server during app bootstrap.
Eureka Client Eureka also comes with a Java-based client component, the eureka-client, which makes interactions with the service much easier. The client also has a built-in load balancer that does basic round-robin load balancing. Each microservice in the distributed ecosystem much include this client to communicate and register with eureka-server.
Typical usecase for Eureka
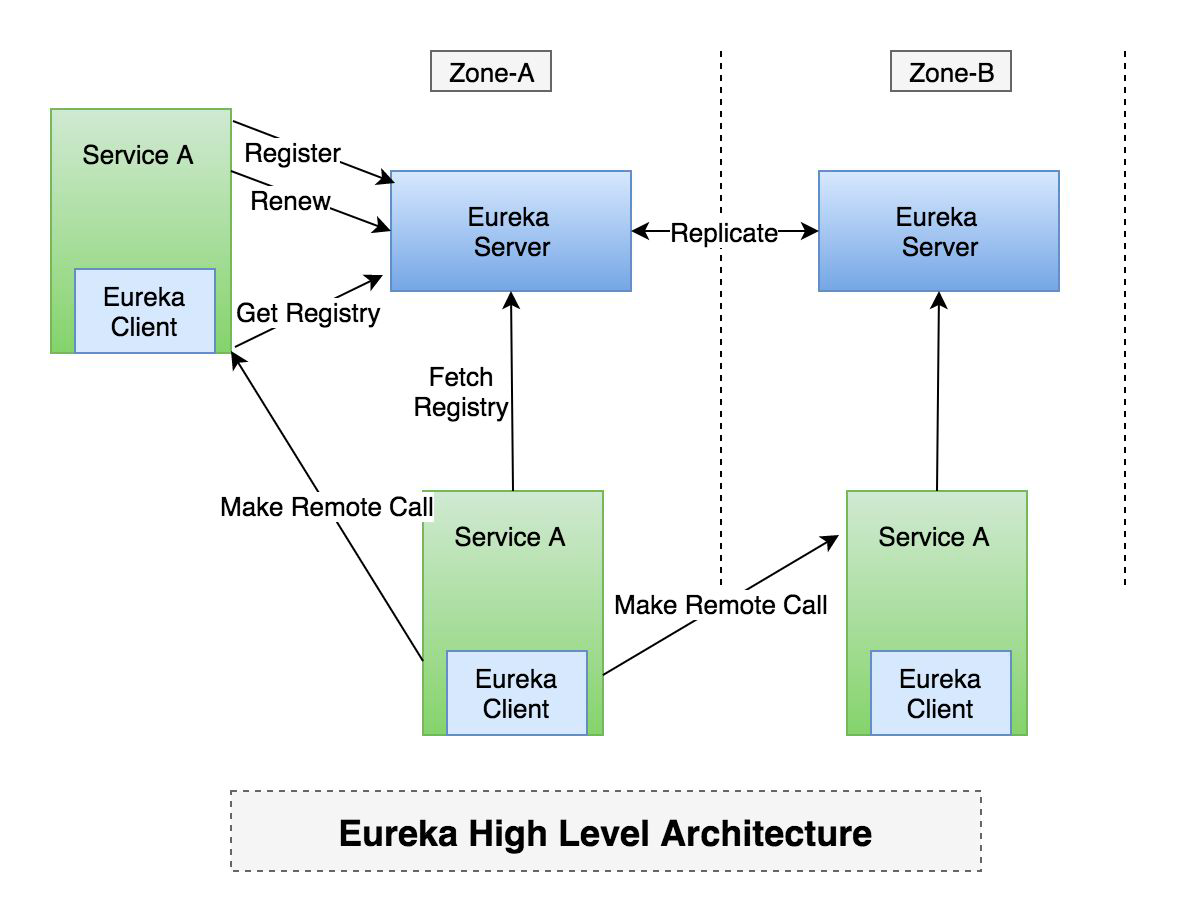
There is usually one eureka server cluster per region (us, asia, europe, australia) which knows only about instances in its region. Services register with Eureka and then send heartbeats to renew their leases every 30 seconds. If the service can not renew their lease for few times, it is taken out of server registry in about 90 seconds. The registration information and the renewals are replicated to all the eureka nodes in the cluster. The clients from any zone can look up the registry information (happens every 30 seconds) to locate their services (which could be in any zone) and make remote calls.
Eureka clients are built to handle the failure of one or more Eureka servers. Since Eureka clients have the registry cache information in them, they can operate reasonably well, even when all of the eureka servers go down.
More Information about eureka: https://github.com/Netflix/eureka/wiki/Eureka-at-a-glance
Externalize configuration in a distributed system
Spring Cloud Config provides server and client side support for externalized configuration in a distributed system. With a config server we have a central place to manage external properties for applications across all environments. The default implementation of the config-server storage uses git so it easily supports labelled versions of configuration environments.
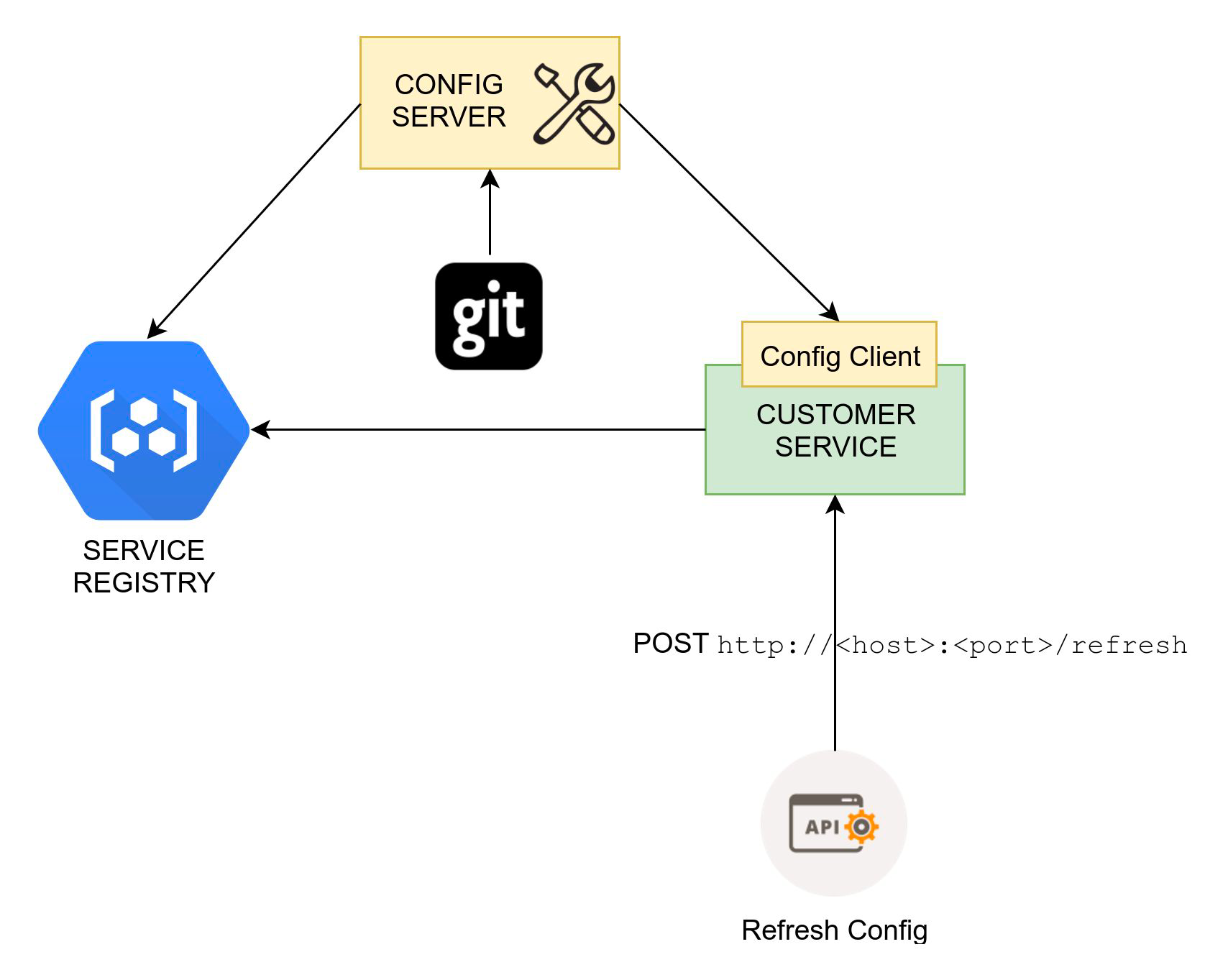
Key features of Spring Cloud config-server
- HTTP, resource-based API for external configuration (YAML or properties syntax)
- Encrypt and Decrypt property values - both symmetric and asymmetric encryption is supported
- Very easy to create a standalone config server with use of
@EnableConfigServer
Key features in Spring Cloud config-client
- Encrypt and Decrypt property values
- Bind to Config Server and Initialize Spring Environment with remote property sources.
@RefreshScopefor Spring @Beans that want to be re-initialized when configuration changes.
Refresh configuration changes on the fly in Spring Cloud environment
Using config-server, its possible to refresh the configuration on the fly. The configuration changes will only be picked by Beans that are declared with @RefreshScope annotation.
The following code illustrates the same. The property message is defined in the config-server and changes to this property can be made at runtime without restarting the microservices.
package hello;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.context.config.annotation.RefreshScope;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@SpringBootApplication
public class ConfigClientApplication {
public static void main(String[] args) {
SpringApplication.run(ConfigClientApplication.class, args);
}
}
@RefreshScope
@RestController
class MessageRestController {
@Value("${message:Hello World}")
private String message;
@RequestMapping("/message")
String getMessage() {
return this.message;
}
}
@RefreshScope makes it possible to dynamically reload the configuration for this bean.
Achieve client side load balancing in Spring Microservices using Spring Cloud
Naive approach would be to get list of instances of a microservice using discovery client and then randomly pickup one instance and make the call. But that’s not easy because that service instance may be down at the moment and we will have to retry the call again on next available instance.
Ribbon does that all internally. Ribbon will do at-least the following-
- A central concept in Ribbon is that of the named client. more about named clients.
- Load balance based on some algorithm: round-robin (RR) rule by default or WeightedResponseTimeRule, AvailabilityFilteringRule, etc can be chosen.
- Make calls to next server if first one fails
- Its easy to use Hystrix with Ribbon and use circuit breaker for managing fault tolerance.
- Establishing affinity between clients and servers by dividing them into zones (like racks in a data center) and favor servers in the same zone to reduce latency.
- Keeping statistics of servers and avoid servers with high latency or frequent failures.
- Keeping statistics of zones and avoid zones that might be in outage.
Under the hood, Ribbon Load Balancer uses the following 3 components-
- Rule - a logic component to determine which server to return from a list
- Ping - a component running in background to ensure liveness of servers
- ServerList - this can be static or dynamic. If it is dynamic (as used by DynamicServerListLoadBalancer), a background thread will refresh and filter the list at certain interval.
We shall always use Ribbon, a client side load balancing library to distribute the load among various instance of a microservice deployment.
- Using Ribbon with RestTemplate.
- Using Ribbon with Feign Client.
Client side load-balancer Ribbon in your microservices architecture
Ribbon - a client side load-balancer can be used in Spring Cloud powered microservices to distribute the API call load among different instances of a single service. Following steps need to be taken:
Add required dependency in build.gradle
compile(‘org.springframework.cloud:spring-cloud-starter-ribbon’)
Now we need to configure the application.yml for proper Ribbon settings. /src/main/resources/application.yml.
ribbon:
ConnectTimeout: 60000
ReadTimeout: 60000
MaxAutoRetries: 1
MaxAutoRetriesNextServer: 1
OkToRetryOnAllOperations: true
http:
client:
enabled: true
Create LoadBalanced RestTemplate Bean
Finally, you need to annotate RestTemplate bean with LoadBalanced annotation to enable Ribbon client side load-balancer.
@LoadBalanced
@Bean
RestTemplate restTemplate(RestTemplateBuilder restTemplateBuilder) {
return restTemplateBuilder.build();
}
Now whatever calls you make using this RestTemplate, will be load balanced using default round-robin fashion.
Use both LoadBalanced as well as normal RestTemplate object in the single microservice
We can create two different beans with different qualifiers, one with load balanced configuration another without ribbon load balancer. Defining Normal and LoadBalanced RestTemplate with two different Bean names.
@LoadBalanced
@Bean(name = "loadBalancedRestTemplate")
RestTemplate restTemplate(RestTemplateBuilder restTemplateBuilder) {
return restTemplateBuilder.build();
}
@Bean(name = "simpleRestTemplate")
public RestTemplate simpleRestTemplate(RestTemplateBuilder restTemplateBuilder) {
RestTemplate restTemplate = restTemplateBuilder.build();
return restTemplate;
}
- Load Balanced RestTemplate bean
- Normal RestTemplate bean
Wiring Normal RestTemplate using @Qualifier.
@Autowired
@Qualifier("simpleRestTemplate")
private RestTemplate restTemplate;
Use of Eureka for service discovery in Ribbon Load Balancer
If both Ribbon and Eureka libraries are present on the classpath, Ribbon is automatically configured with Eureka i.e. Server list is populated from Eureka, Ping functionality is delegated to Eureka to check if a server is up. This approach is very convenient in any enterprise grade application.